This is part 5 of 6 in a series discussing the principles behind the “ready state” and other concepts implemented in OpenCrowbar. The content is reposted from the OpenCrowbar docs repo.
Attribute Injection
Attribute Injection is an essential aspect of the “FuncOps” story because it helps clean boundaries needed to implement consistent scripting behavior between divergent sites.
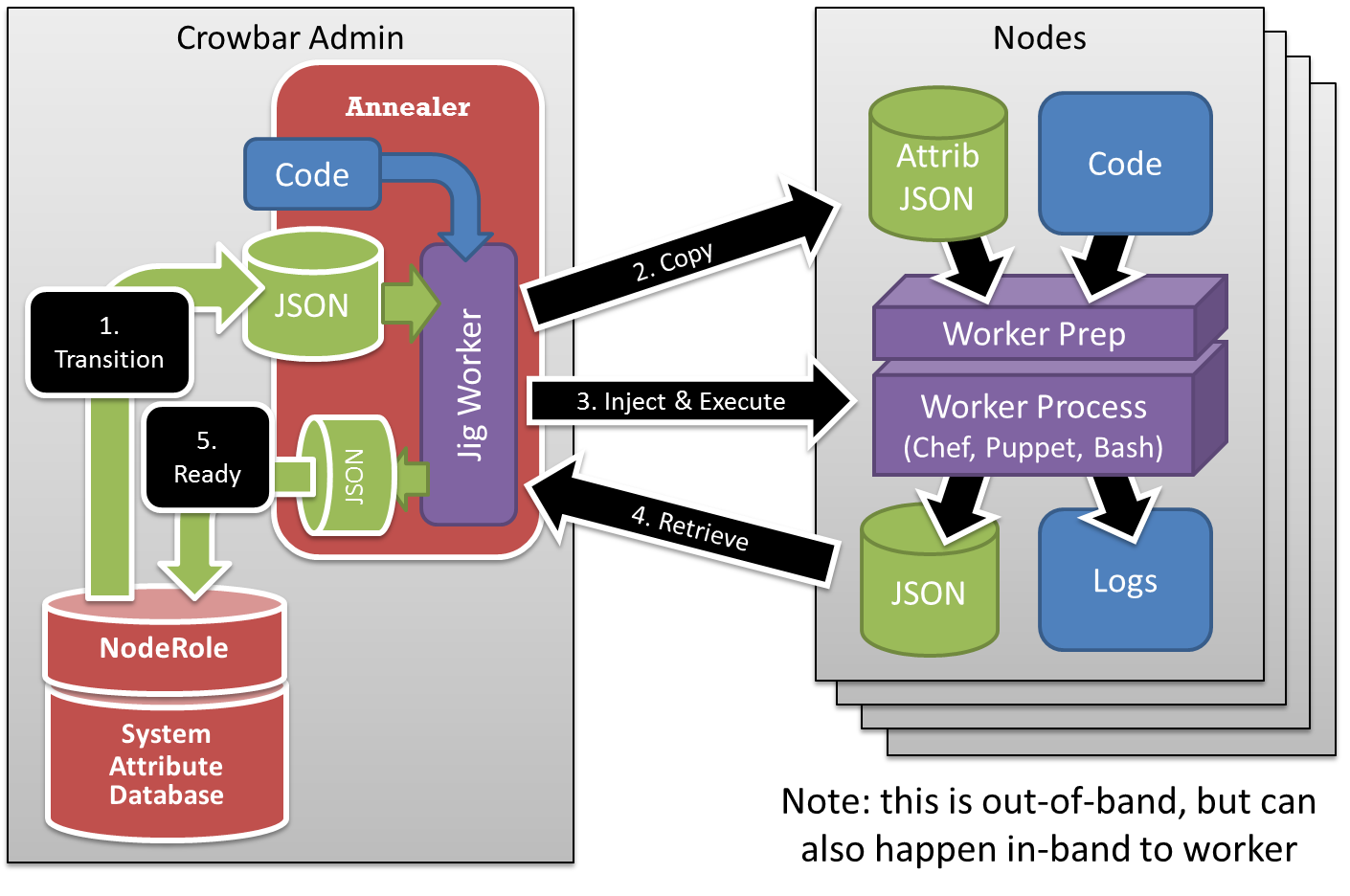 It also allows Crowbar to abstract and isolate provisioning layers. This operational approach means that deployments are composed of layered services (see emergent services) instead of locked “golden” images. The layers can be maintained independently and allow users to compose specific configurations a la cart. This approach works if the layers have clean functional boundaries (FuncOps) that can be scoped and managed atomically.
It also allows Crowbar to abstract and isolate provisioning layers. This operational approach means that deployments are composed of layered services (see emergent services) instead of locked “golden” images. The layers can be maintained independently and allow users to compose specific configurations a la cart. This approach works if the layers have clean functional boundaries (FuncOps) that can be scoped and managed atomically.
To explain how Attribute Injection accomplishes this, we need to explore why search became an anti-pattern in Crowbar v1. Originally, being able to use server based search functions in operational scripting was a critical feature. It allowed individual nodes to act as part of a system by searching for global information needed to make local decisions. This greatly added Crowbar’s mission of system level configuration; however, it also created significant hidden interdependencies between scripts. As Crowbar v1 grew in complexity, searches became more and more difficult to maintain because they were difficult to correctly scope, hard to centrally manage and prone to timing issues.
Crowbar was not unique in dealing with this problem – the Attribute Injection pattern has become a preferred alternative to search in integrated community cookbooks.
Attribute Injection in OpenCrowbar works by establishing specific inputs and outputs for all state actions (NodeRole runs). By declaring the exact inputs needed and outputs provided, Crowbar can better manage each annealing operation. This control includes deployment scoping boundaries, time sequence of information plus override and substitution of inputs based on execution paths.
This concept is not unique to Crowbar. It has become best practice for operational scripts. Crowbar simply extends to paradigm to the system level and orchestration level.
Attribute Injection enabled operations to be:
- Atomic – only the information needed for the operation is provided so risk of “bleed over” between scripts is minimized. This is also a functional programming preference.
- Isolated Idempotent – risk of accidentally picking up changed information from previous runs is reduced by controlling the inputs. That makes it more likely that scripts can be idempotent.
- Cleanly Scoped – information passed into operations can be limited based on system deployment boundaries instead of search parameters. This allows the orchestration to manage when and how information is added into configurations.
- Easy to troubleshoot – since the information is limited and controlled, it is easier to recreate runs for troubleshooting. This is a substantial value for diagnostics.

Pingback: Ops is Ops, except when it ain’t. Breaking down the impedance mismatches between physical and cloud ops. | Rob Hirschfeld
Pingback: why is hardware hard? Ready State Physical Ops Meetup on Tuesday 12/2 9am PT | Rob Hirschfeld
Pingback: Delicious 7 Layer DIP (DevOps Infrastructure Provisioning) model with graphic! | Rob Hirschfeld