While “ready state” as a concept has been getting a lot of positive response, I forget that much of the innovation and learning behind that concept never surfaced as posts here. The Anvil (2.0) release included the OpenCrowbar team cataloging our principles in docs. Now it’s time to repost the team’s work into a short series over the next three days.
In architecting the Crowbar operational model, we’ve consistently twisted adapted traditional computer science concepts like late binding, simulated annealing, emergent behavior, attribute injection and functional programming to create a repeatable platform for sharing open operations practice (post 2).
Functional DevOps aka “FuncOps”
Ok, maybe that’s not going to be the 70’s era hype bubble name, but… the operational model behind Crowbar is entering its third generation and its important to understand the state isolation and integration principles behind that model is closer to functional than declarative programming.

Parliament is Crowbar’s official FuncOps sound track
The model is critical because it shapes how Crowbar approaches the infrastructure at a fundamental level so it makes it easier to interact with the platform if you see how we are approaching operations. Crowbar’s goal is to create emergent services.
We’ll expore those topics in this series to explain Crowbar’s core architectural principles. Before we get into that, I’d like to review some history.
The Crowbar Objective
Crowbar delivers repeatable best practice deployments. Crowbar is not just about installation: we define success as a sustainable operations model where we continuously improve how people use their infrastructure. The complexity and pace of technology change is accelerating so we must have an approach that embraces continuous delivery.
Crowbar’s objective is to help operators become more efficient, stable and resilient over time.
Background
When Greg Althaus (github @GAlhtaus) and Rob “zehicle” Hirschfeld (github @CloudEdge) started the project, we had some very specific targets in mind. We’d been working towards using organic emergent swarming (think ants) to model continuous application deployment. We had also been struggling with the most routine foundational tasks (bios, raid, o/s install, networking, ops infrastructure) when bringing up early scale cloud & data applications. Another key contributor, Victor Lowther (github @VictorLowther) has critical experience in Linux operations, networking and dependency resolution that lead to made significant contributions around the Annealing and networking model. These backgrounds heavily influenced how we approached Crowbar.
First, we started with best of field DevOps infrastructure: Opscode Chef. There was already a remarkable open source community around this tool and an enthusiastic following for cloud and scale operators . Using Chef to do the majority of the installation left the Crowbar team to focus on
 Key Features
Key Features
- Heterogeneous Operating Systems – chose which operating system you want to install on the target servers.
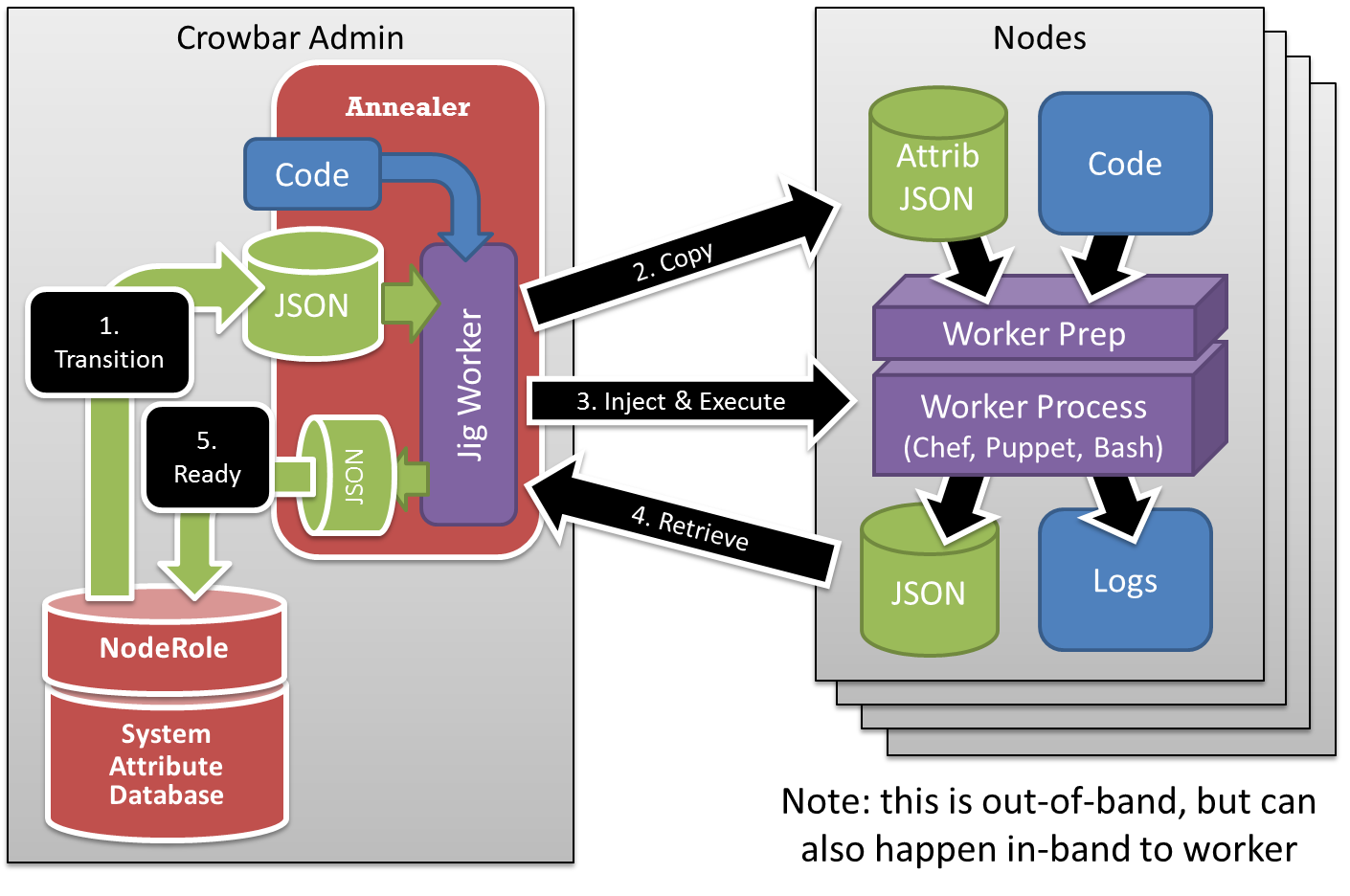
- CMDB Flexibility (see picture) – don’t be locked in to a devops toolset. Attribute injection allows clean abstraction boundaries so you can use multiple tools (Chef and Puppet, playing together).
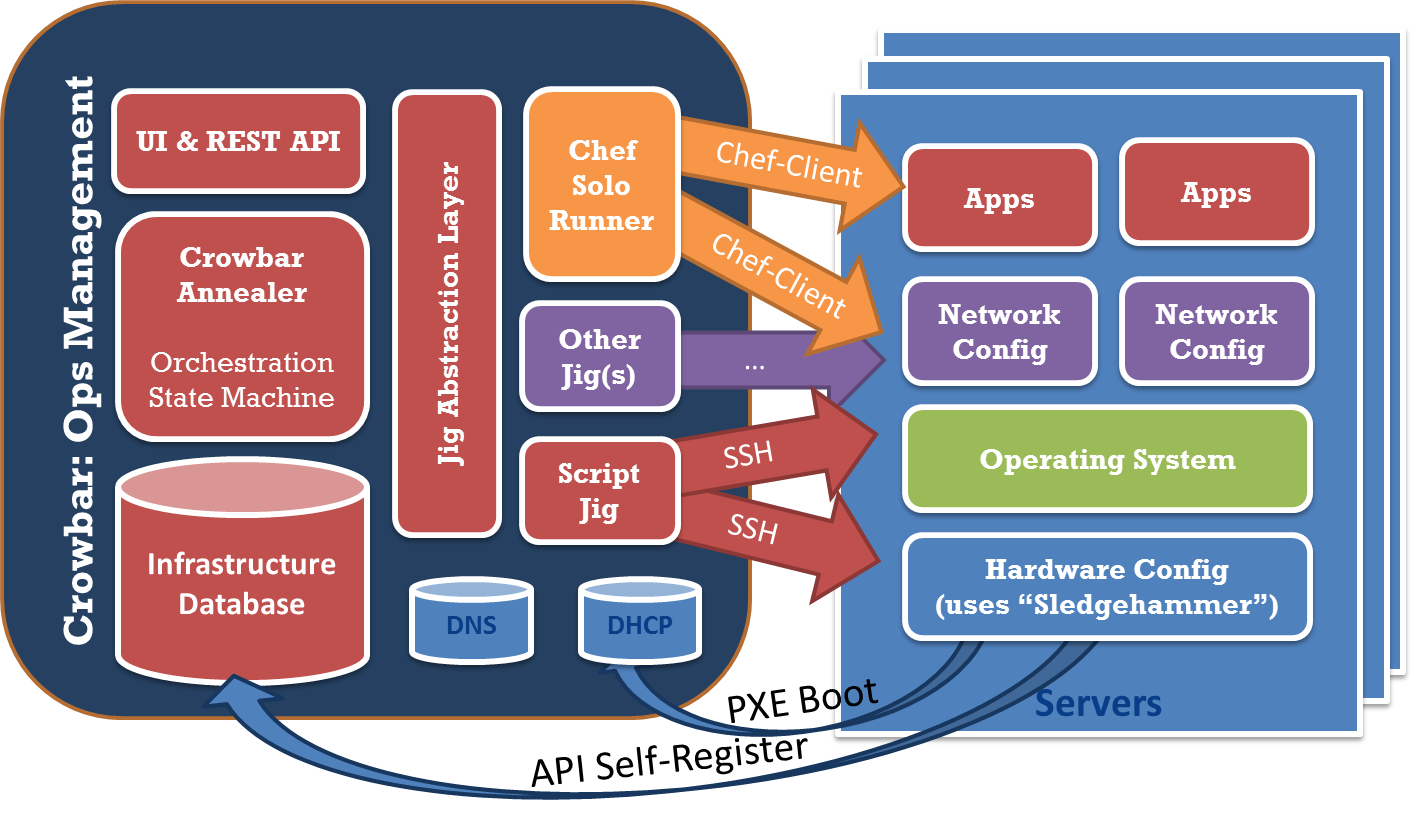
- Ops Annealer –the orchestration at Crowbar’s heart combines the best of directed graphs with late binding and parallel execution. We believe annealing is the key ingredient for repeatable and OpenOps shared code upgrades
- Upstream Friendly – infrastructure as code works best as a community practice and Crowbar use upstream code
- without injecting “crowbarisms” that were previously required. So you can share your learning with the broader DevOps community even if they don’t use Crowbar.
- Node Discovery (or not) – Crowbar maintains the same proven discovery image based approach that we used before, but we’ve streamlined and expanded it. You can use Crowbar’s API outside of the PXE discovery system to accommodate Docker containers, existing systems and VMs.
- Hardware Configuration – Crowbar maintains the same optional hardware neutral approach to RAID and BIOS configuration. Configuring hardware with repeatability is difficult and requires much iterative testing. While our approach is open and generic, the team at Dell works hard to validate a on specific set of gear: it’s impossible to make statements beyond that test matrix.
- Network Abstraction – Crowbar dramatically extended our DevOps network abstraction. We’ve learned that a networking is the key to success for deployment and upgrade so we’ve made Crowbar networking flexible and concise. Crowbar networking works with attribute injection so that you can avoid hardwiring networking into DevOps scripts.
- Out of band control – when the Annealer hands off work, Crowbar gives the worker implementation flexibility to do it on the node (using SSH) or remotely (using an API). Making agents optional means allows operators and developers make the best choices for the actions that they need to take.
- Technical Debt Paydown – We’ve also updated the Crowbar infrastructure to use the latest libraries like Ruby 2, Rails 4, Chef 11. Even more importantly, we’re dramatically simplified the code structure including in repo documentation and a Docker based developer environment that makes building a working Crowbar environment fast and repeatable.
OpenCrowbar (CB2) vs Crowbar (CB1)?
Why change to OpenCrowbar? This new generation of Crowbar is structurally different from Crowbar 1 and we’ve investing substantially in refactoring the tooling, paying down technical debt and cleanup up documentation. Since Crowbar 1 is still being actively developed, splitting the repositories allow both versions to progress with less confusion. The majority of the principles and deployment code is very similar, I think of Crowbar as a single community.
Continue Reading > post 2
 Progress and investment have been substantial and, happily, organic. Like many platforms, it’s success relies on a reasonable balance between strong opinions about “right” patterns and enough flexibility to accommodate exceptions.
Progress and investment have been substantial and, happily, organic. Like many platforms, it’s success relies on a reasonable balance between strong opinions about “right” patterns and enough flexibility to accommodate exceptions.