Note: Cross posted on Dell Tech Center Blogs.
 Background: Crowbar is an open source cloud deployment framework originally developed by Dell to support our OpenStack and Hadoop powered solutions. Recently, it’s scope has increased to include a DevOps operations model and other deployments for additional cloud applications.
Background: Crowbar is an open source cloud deployment framework originally developed by Dell to support our OpenStack and Hadoop powered solutions. Recently, it’s scope has increased to include a DevOps operations model and other deployments for additional cloud applications.
It’s only been a matter of months since we open sourced the Dell Crowbar Project at OSCON in June 2011; however, the progress and response to the project has been over whelming. Crowbar is transforming into a community tool that is hardware, operating system, and application agnostic. With that in mind, it’s time for me to provide a recap of Crowbar for those just learning about the project.
Crowbar started out simply as an installer for the “Dell OpenStack™-Powered Cloud Solution” with the objective of deploying a cloud from unboxed servers to a completely functioning system in under four hours. That meant doing all the BIOS, RAID, Operations services (DNS, NTP, DHCP, etc.), networking, O/S installs and system configuration required creating a complete cloud infrastructure. It was a big job, but one that we’d been piecing together on earlier cloud installation projects. A key part of the project involved collaborating with Opscode Chef Server on the many system configuration tasks. Ultimately, we met and exceeded the target with a complete OpenStack install in less than two hours.
In the process of delivering Crowbar as an installer, we realized that Chef, and tools like it, were part of a larger cloud movement known as DevOps.
The DevOps approach to deployment builds up systems in a layered model rather than using packaged images. This layered model means that parts of the system are relatively independent and highly flexible. Users can choose which components of the system they want to deploy and where to place those components. For example, Crowbar deploys Nagios by default, but users can disable that component in favor of their own monitoring system. It also allows for new components to identify that Nagios is available and automatically register themselves as clients and setup application specific profiles. In this way, Crowbar’s use of a DevOps layered deployment model provides flexibility for BOTH modularized and integrated cloud deployments.
We believe that operations that embrace layered deployments are essential for success because they allow our customers to respond to the accelerating pace of change. We call this model for cloud data centers “CloudOps.”
Based on the flexibility of Crowbar, our team decided to use it as the deployment model for our Apache™ Hadoop™ project (“Dell | Apache Hadoop Solution”). While a good fit, adding Hadoop required expanding Crowbar in several critical ways.
- We had to make major changes in our installation and build processes to accommodate multi-operating system support (RHEL 5.6 and Ubuntu 10.10 as of Oct 2011).
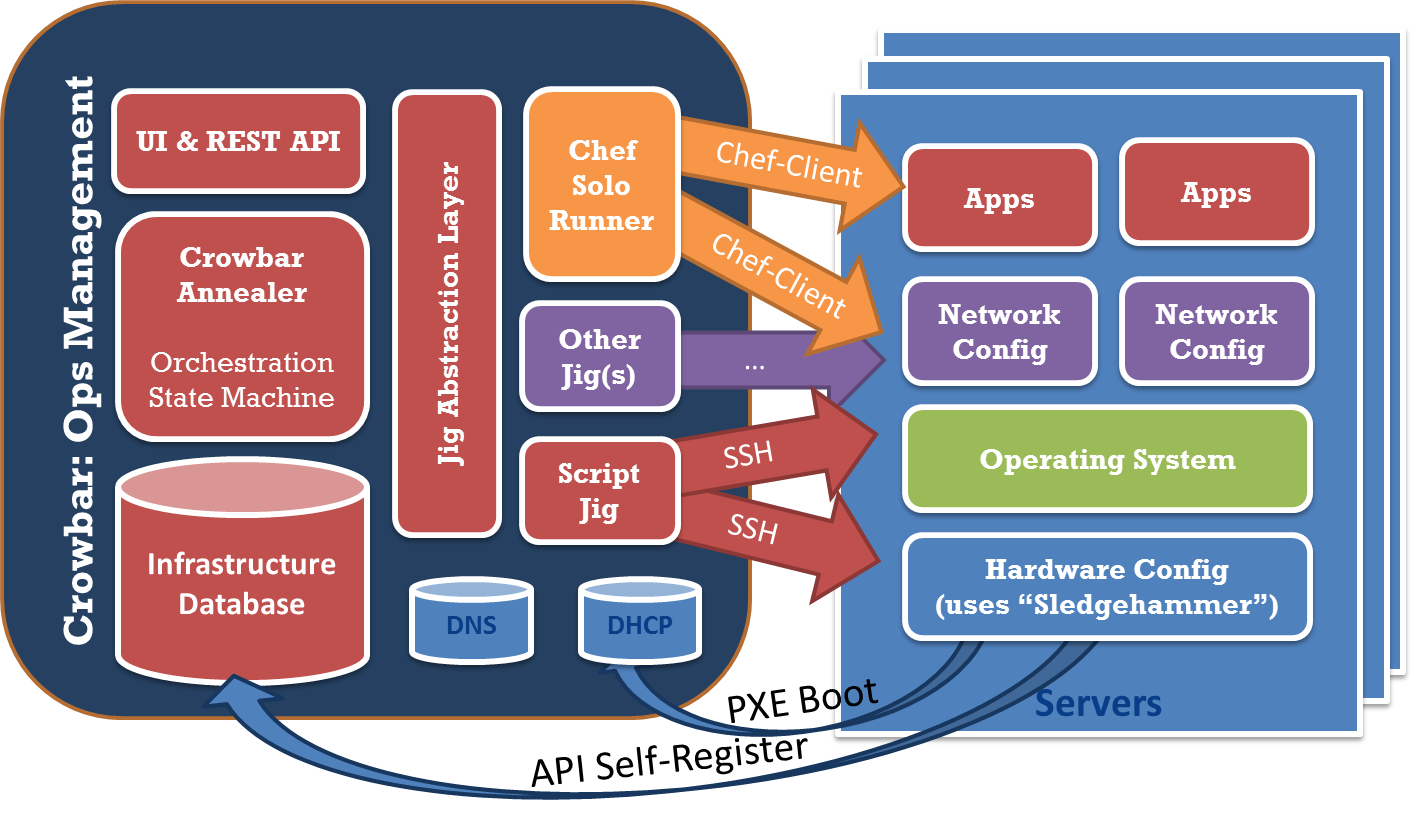
- We introduced a modularization concept that we call “barclamps” that package individual layers of the deployment infrastructure. These barclamps reach from the lowest system levels (IPMI, BIOS, and RAID) to the highest (OpenStack and Hadoop).
Barclamps are a very significant architecture pattern for Crowbar:
- They allow other applications to plug into the framework and leverage other barclamps in the solution. For example, VMware created a Cloud Foundry barclamp and Dream Host has created a Ceph barclamp. Both barclamps are examples of applications that can leverage Crowbar for a repeatable and predictable cloud deployment.
- They are independent modules with their own life cycle. Each one has its own code repository and can be imported into a live system after initial deployment. This allows customers to expand and manage their system after initial deployment.
- They have many components such as Chef Cookbooks, custom UI for configuration, dependency graphs, and even localization support.
- They offer services that other barclamps can consume. The Network barclamp delivers many essential services for bootstrapping clouds including IP allocation, NIC teaming, and node VLAN configuration.
- They can provide extensible logic to evaluate a system and make deployment recommendations. So far, no barclamps have implemented more than the most basic proposals; however, they have the potential for much richer analysis.
Making these changes was a substantial investment by Dell, but it greatly expands the community’s ability to participate in Crowbar development. We believe these changes were essential to our team’s core values of open and collaborative development.
Most recently, our team moved Crowbar development into the open. This change was reflected in our work on OpenStack Diablo (+ Keystone and Dashboard) with contributions by Opscode and Rackspace Cloud Builders. Rather than work internally and push updates at milestones, we are now coding directly from the Crowbar repositories on Github. It is important to note that for licensing reasons, Dell has not open sourced the optional BIOS and RAID barclamps. This level of openness better positions us to collaborate with the crowbar community.
For a young project, we’re very proud of the progress that we’ve made with Crowbar. We are starting a new chapter that brings new challenges such as expanding community involvement, roadmap transparency, and growing Dell support capabilities. You will also begin to see optional barclamps that interact with proprietary and licensed hardware and software. All of these changes are part of growing Crowbar in framework that can support a vibrant and rich ecosystem.
We are doing everything we can to make it easy to become part of the Crowbar community. Please join our mailing list, download the open source code or ISO, create a barclamp, and make your voice heard. Since Dell is funding the core development on this project, contacting your Dell salesperson and telling them how much you appreciate our efforts goes a long way too.