What is a Google SRE? Charity Majors gave a great overview on Datanauts #65, Susan Fowler from Uber talks about “no ops” tensions and Patrick Hill from Atlassian wrote up a good review too. This is not new: Ben Treynor defined it back in 2014.
DevOps is under attack.
Well, not DevOps exactly but the common misconception that DevOps is about Developers doing Ops (it’s really about lean process, system thinking, and positive culture). It turns out the Ops is hard and, as I recently discussed with John Furrier, developers really really don’t want be that focused on infrastructure.
In fact, I see containers and serverless as a “developers won’t waste time on ops revolt.” (I discuss this more in my 2016 retrospective).
The tension between Ops and Dev goes way back and has been a source of confusion for me and my RackN co-founders. We believe we are developers, except that we spend our whole time focused on writing code for operations. With the rise of Site Reliability Engineers (SRE) as a job classification, our type of black swan engineer is being embraced as a critical skill. It’s recognized as the only way to stay ahead of our ravenous appetite for computing infrastructure.
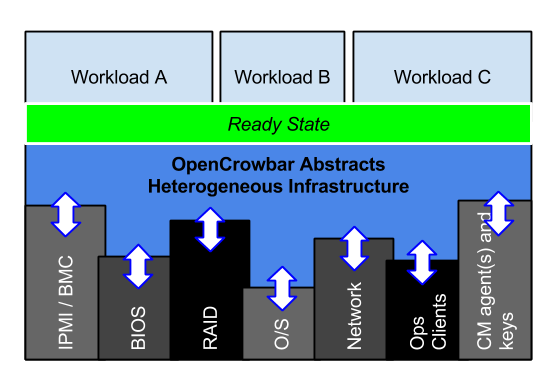
I’ve been writing about Site Reliability Engineering (SRE) tasks for nearly 5 years under a lot of different names such as DevOps, Ready State, Open Operations and Underlay Operations. SRE is a term popularized by Google (there’s a book!) for the operators who build and automate their infrastructure. Their role is not administration, it is redefining how infrastructure is used and managed within Google.
Using infrastructure effectively is a competitive advantage for Google and their SREs carry tremendous authority and respect for executing on that mission.
 Meanwhile, we’re in the midst of an Enterprise revolt against running infrastructure. Companies, for very good reasons, are shutting down internal IT efforts in favor of using outsourced infrastructure. Operations has simply not been able to complete with the capability, flexibility and breadth of infrastructure services offered by Amazon.
Meanwhile, we’re in the midst of an Enterprise revolt against running infrastructure. Companies, for very good reasons, are shutting down internal IT efforts in favor of using outsourced infrastructure. Operations has simply not been able to complete with the capability, flexibility and breadth of infrastructure services offered by Amazon.
SRE is about operational excellence and we keep up with the increasingly rapid pace of IT. It’s a recognition that we cannot scale people quickly as we add infrastructure. And, critically, it is not infrastructure specific.
Over the next year, I’ll continue to dig deeply into the skills, tools and processes around operations. I think that SRE may be the right banner for these thoughts and I’d like to hear your thoughts about that.
MORE? Here’s the next post in the series about Spiraling Ops Debt. Or Skip to Podcasts with Eric Wright and Stephen Spector.

 I’ve struggled with the term “underlay” for infrastructure of a long time. At
I’ve struggled with the term “underlay” for infrastructure of a long time. At 


 ere’s the notice from the
ere’s the notice from the 