Applying architecture and computer science principles to infrastructure automation helps us build better controls. In this post, we create an OSI-like model that helps decompose the ops environment.
The RackN team discussions about “what is Ready State” have led to some interesting realizations about physical ops. One of the most critical has been splitting the operational configuration (DNS, NTP, SSH Keys, Monitoring, Security, etc) from the application configuration.
Interactions between these layers is much more dynamic than developers and operators expect.
In cloud deployments, you can use ask for the virtual infrastructure to be configured in advance via the IaaS and/or golden base images. In hardware, the environment build up needs to be more incremental because that variations in physical infrastructure and operations have to be accommodated.
Greg Althaus, Crowbar co-founder, and I put together this 7 layer model (it started as 3 and grew) because we needed to be more specific in discussion about provisioning and upgrade activity. The system view helps explain how layer 5 and 6 operate at the system layer.
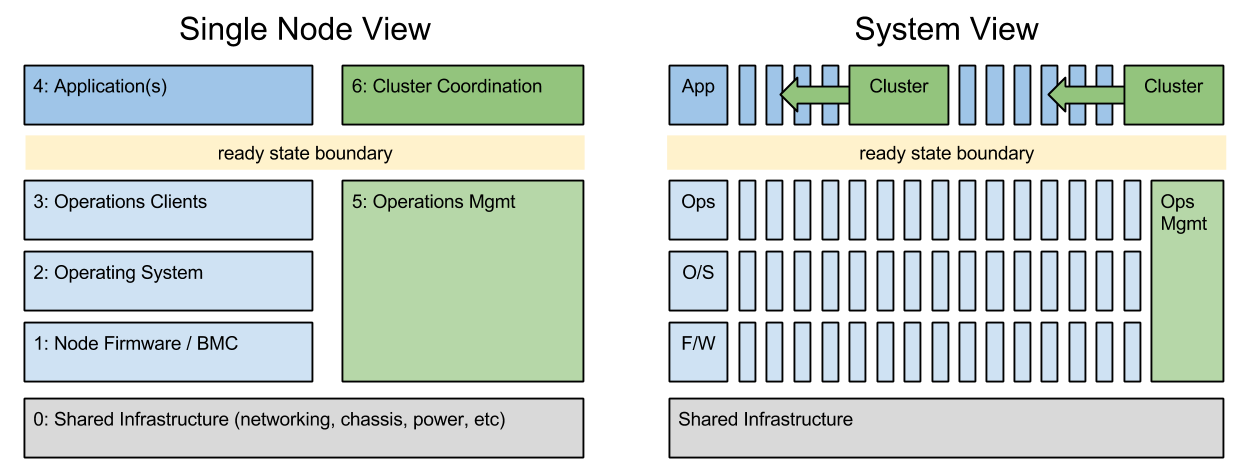
The Seven Layers of our DIP:
- shared infrastructure – the base layer is about the interconnects between the nodes. In this model, we care about the specific linkage to the node: VLAN tags on the switch port, which switch is connected, which PDU ID controls turns it on.
- firmware and management – nodes have substantial driver (RAID/BIOS/IPMI) software below the operating system that must be configured correctly. In some cases, these configurations have external interfaces (BMC) that require out-of-band access while others can only be configured in pre-install environments (I call that side-band).
- operating system – while the operating system is critical, operators are striving to keep this layer as thin to avoid overhead. Even so, there are critical security, networking and device mapping functions that must be configured. Critical local resource management items like mapping media or building network teams and bridges are level 2 functions.
- operations clients – this layer connects the node to the logical data center infrastructure is basic ways like time synch (NTP) and name resolution (DNS). It’s also where more sophisticated operators configure things like distributed cache, centralized logging and system health monitoring. CMDB agents like Chef, Puppet or Saltstack are installed at the “top” of this layer to complete ready state.
- applications – once all the baseline is setup, this is the unique workload. It can range from platforms for other applications (like OpenStack or Kubernetes) or the software itself like Ceph, Hadoop or anything.
- operations management – the external system references for layer 3 must be factored into the operations model because they often require synchronized configuration. For example, registering a server name and IP addresses in a DNS, updating an inventory database or adding it’s thresholds to a monitoring infrastructure. For scale and security, it is critical to keep the node configuration (layer 3) constantly synchronized with the central management systems.
- cluster coordination – no application stands alone; consequently, actions from layer 4 nodes must be coordinated with other nodes. This ranges from database registration and load balancing to complex upgrades with live data migration. Working in layer 4 without layer 6 coordination creates unmanageable infrastructure.
This seven layer operations model helps us discuss which actions are required when provisioning a scale infrastructure. In my experience, many developers want to work exclusively in layer 4 and overlook the need to have a consistent and managed infrastructure in all the other layers. We enable this thinking in cloud and platform as a service (PaaS) and that helps improve developer productivity.
We cannot overlook the other layers in physical ops; however, working to ready state helps us create more cloud-like boundaries. Those boundaries are a natural segue my upcoming post about functional operations (older efforts here).
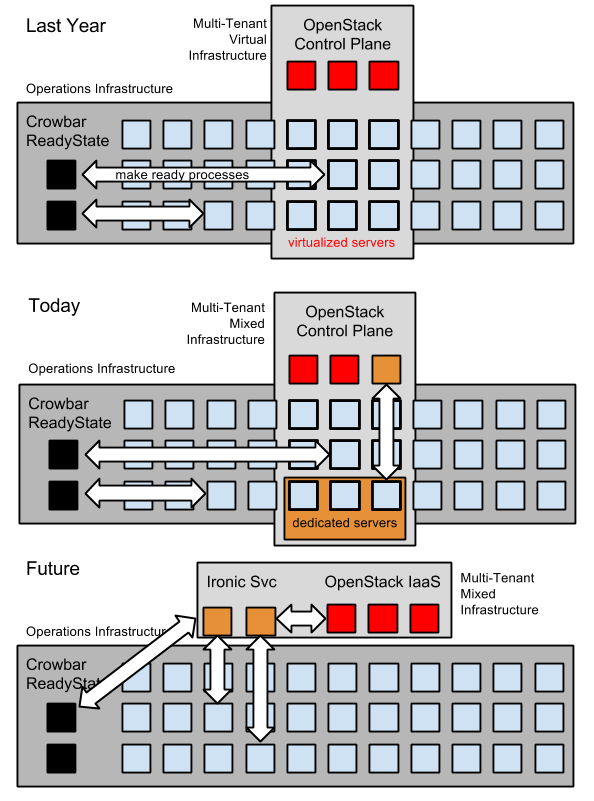




 Today, we’re ready to help people run and expand OpenCrowbar (days away from v2.1!). We’re also seeking investment to make the project more “enterprise-ready” and build integrations that extend ready state.
Today, we’re ready to help people run and expand OpenCrowbar (days away from v2.1!). We’re also seeking investment to make the project more “enterprise-ready” and build integrations that extend ready state.


