Update 12/14/16: Docker announced that they would create a container engine only project, ContinainerD, to decouple the engine from management layers above. Hopefully this addresses this issues outlined in the post below.
Monday, The New Stack broke news about a possible fork of the Docker Engine and prominently quoted me saying “Docker consistently breaks backend compatibility.” The technical instability alone is not what’s prompting industry leaders like Google, Red Hat and Huawei to take drastic and potentially risky community action in a central project.
So what’s driving a fork? It’s the intersection of Cash, Complexity and Community.
 In fact, I’d warned about this risk over a year ago: Docker is both a core infrastucture technology (the docker container runner, aka Docker Engine) and a commercial company that manages the Docker brand. The community formed a standard, runC, to try and standardize; however, Docker continues to deviate from (or innovate faster) that base.
In fact, I’d warned about this risk over a year ago: Docker is both a core infrastucture technology (the docker container runner, aka Docker Engine) and a commercial company that manages the Docker brand. The community formed a standard, runC, to try and standardize; however, Docker continues to deviate from (or innovate faster) that base.
It’s important for me to note that we use Docker tools and technologies heavily. So far, I’ve been a long-time advocate and user of Docker’s innovative technology. As such, we’ve also had to ride the rapid release roller coaster.
Let’s look at what’s going on here in three key areas:
1. Cash
The expected monetization of containers is the multi-system orchestration and support infrastructure. Since many companies look to containers as leading the disruptive next innovation wave, the idea that Docker is holding part of their plans hostage is simply unacceptable.
So far, the open source Docker Engine has been simply included without payment into these products. That changed in version 1.12 when Docker co-mingled their competitive Swarm product into the Docker Engine. That effectively forces these other parties to advocate and distribute their competitors product.
2. Complexity
When Docker added cool Swarm Orchestration features into the v1.12 runtime, it added a lot of complexity too. That may be simple from a “how many things do I have to download and type” perspective; however, that single unit is now dragging around a lot more code.
In one of the recent comments about this issue, Bob Wise bemoaned the need for infrastructure to be boring. Even as we look to complex orchestration like Swarm, Kubernetes, Mesos, Rancher and others to perform application automation magic, we also need to reduce complexity in our infrastructure layers.
Along those lines, operators want key abstractions like containers to be as simple and focused as possible. We’ve seen similar paths for virtualization runtimes like KVM, Xen and VMware that focus on delivering a very narrow band of functionality very well. There is a lot of pressure from people building with containers to have a similar experience from the container runtime.
This approach both helps operators manage infrastructure and creates a healthy ecosystem of companies that leverage the runtimes.
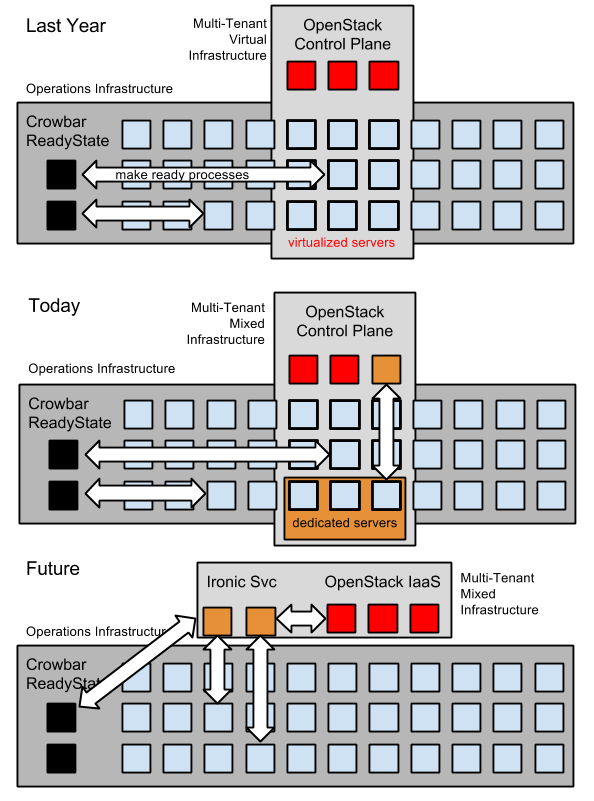
Note: My company, RackN, believes strongly in this need and it’s a core part of our composable approach to automation with Digital Rebar.
3. Community
Multi-vendor open source is a very challenging and specialized type of community. In these communities, most of the contributors are paid by companies with a vested (not necessarily transparent) interest in the project components. If the participants of the community feel that they are not being supported by the leadership then they are likely to revolt.
Ultimately, the primary difference between Docker and a fork of Docker is the brand and the community. If there companies paying the contributors have the will then it’s possible to move a whole community. It’s not cheap, but it’s possible.
Developers vs Operators
One overlooked aspect of this discussion is the apparent lock that Docker enjoys on the container developer community. The three Cs above really focus on the people with budgets (the operators) over the developers. For a fork to succeed, there needs to be a non-Docker set of tooling that feeds the platform pipeline with portable application packages.
In Conclusion…
The world continues to get more and more heterogeneous. We already had multiple container runtimes before Docker and the idea of a new one really is not that crazy right now. We’ve already got an explosion of container orchestration and this is a reflection of that.
My advice? Worry less about the container format for now and focus on automation and abstractions.





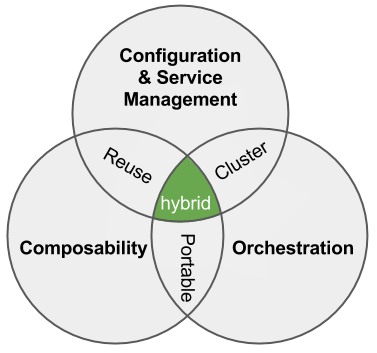 Here’s our write-up:
Here’s our write-up:  I believe that application should drive the infrastructure, not the reverse. I’ve heard may times that the “infrastructure should be invisible to the user.” Unfortunately, lack of abstraction and composibility make it difficult to code across platforms. I like the term “
I believe that application should drive the infrastructure, not the reverse. I’ve heard may times that the “infrastructure should be invisible to the user.” Unfortunately, lack of abstraction and composibility make it difficult to code across platforms. I like the term “