This is part 2 of 6 in a series discussing the principles behind the “ready state” and other concepts implemented in OpenCrowbar. The content is reposted from the OpenCrowbar docs repo.
The operations challenge
A deployment framework is key to solving the problems of deploying, configuring, and scaling open source clusters for cloud computing.
 Deploying an open source cloud can be a complex undertaking. Manual processes, can take days or even weeks working to get a cloud fully operational. Even then, a cloud is never static, in the real world cloud solutions are constantly on an upgrade or improvement path. There is continuous need to deploy new servers, add management capabilities, and track the upstream releases, while keeping the cloud running, and providing reliable services to end users. Service continuity requirements dictate a need for automation and orchestration. There is no other way to reduce the cost while improving the uptime reliability of a cloud.
Deploying an open source cloud can be a complex undertaking. Manual processes, can take days or even weeks working to get a cloud fully operational. Even then, a cloud is never static, in the real world cloud solutions are constantly on an upgrade or improvement path. There is continuous need to deploy new servers, add management capabilities, and track the upstream releases, while keeping the cloud running, and providing reliable services to end users. Service continuity requirements dictate a need for automation and orchestration. There is no other way to reduce the cost while improving the uptime reliability of a cloud.
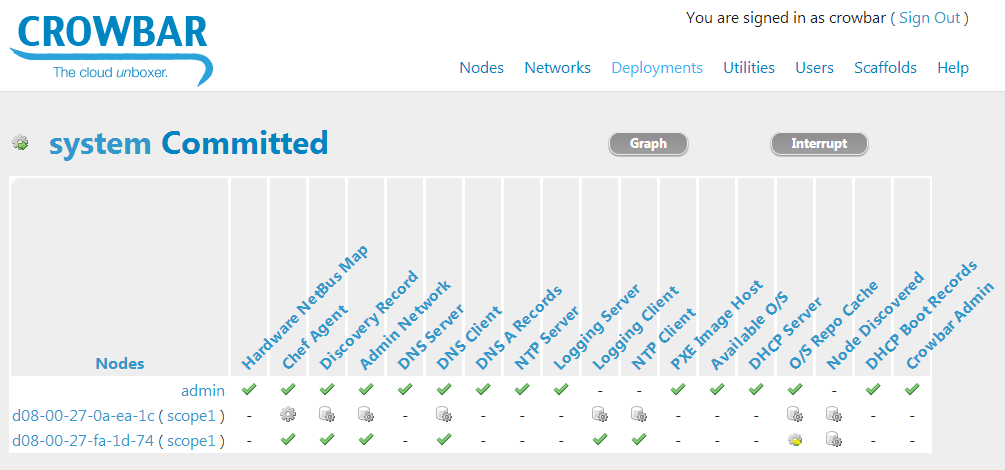
These were among the challenges that drove the development of the OpenCrowbar software framework from it’s roots as an OpenStack installer into a much broader orchestration tool. Because of this evolution, OpenCrowbar has a number of architectural features to address these challenges:
- Abstraction Around OrchestrationOpenCrowbar is designed to simplify the operations of large scale cloud infrastructure by providing a higher level abstraction on top of existing configuration management and orchestration tools based on a layered deployment model.
- Web ArchitectureOpenCrowbar is implemented as a web application server, with a full user interface and a predictable and consistent REST API.
- Platform Agnostic ImplementationOpenCrowbar is designed to be platform and operating system agnostic. It supports discovery and provisioning from a bare metal state, including hardware configuration, updating and configuring BIOS and BMC boards, and operating system installation. Multiple operating systems and heterogeneous operating systems are supported. OpenCrowbar enables use of time-honored tools, industry standard tools, and any form of scriptable facility to perform its state transition operations.
- Modular ArchitectureOpenCrowbar is designed around modular plug-ins called Barclamps. Barclamps allow for extensibility and customization while encapsulating layers of deployment in manageable units.
- State Transition Management EngineThe core of OpenCrowbar is based on a state machine (we call it the Annealer) that tracks nodes, roles, and their relationships in groups called deployments. The state machine is responsible for analyzing dependencies and scheduling state transition operations (transitions).
- Data modelOpenCrowbar uses a dedicated database to track system state and data. As discovery and deployment progresses, system data is collected and made available to other components in the system. Individual components can access and update this data, reducing dependencies through a combination of deferred binding and runtime attribute injection.
- Network AbstractionOpenCrowbar is designed to support a flexible network abstraction, where physical interfaces, BMC’s, VLANS, binding, teaming, and other low level features are mapped to logical conduits, which can be referenced by other components. Networking configurations can be created dynamically to adapt to changing infrastructure.
Continue Reading > post 3