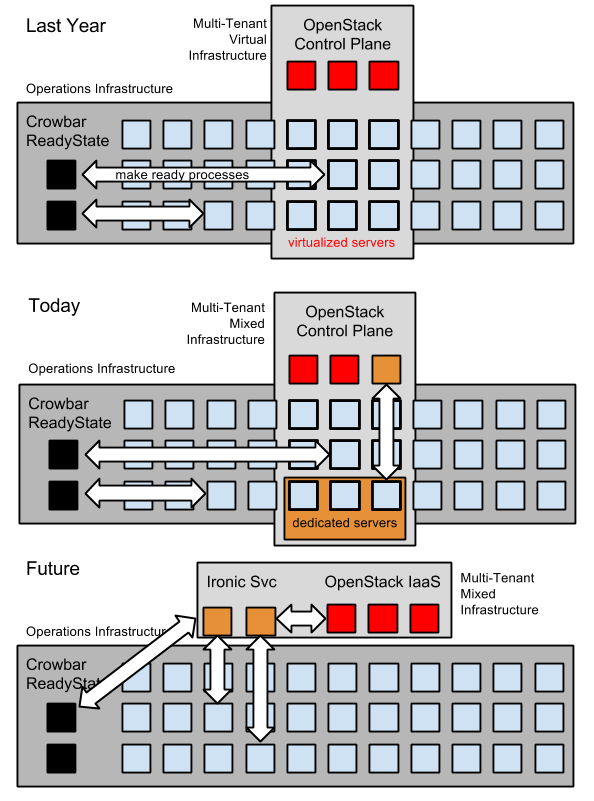
Joining this week’s L8ist Sh9y Podcast is Will Dennis long-time member of the Crowbar community who continues to engage in helping drive Digital Rebar forward. Will is an excellent resource who takes us through the history from Crowbar to Digital Rebar Provision in a way that highlights how the project has changed and why the community scaled back from V2 to the new V3.1.
Topic Time (Minutes.Seconds)
Introduction 0.0 – 1:12
What drew you to Crowbar? 1:12 – 4:29
Secret Language 3:05 – 3:39
Ansible Add-On 4:29 – 5:08
Crowbar v2 5:08 – 6:03
Heterogeneous Infra 6:03 – 8:25
v3 – What had to go? 8:25 – 11:12
Building Infra White Paper 11:12 – 12:07
Cobbler Must Die 12:07 – 12:34
UNIX Concept 12:34 – 13:00
Cobbler Community 13:00 – 16:53
DR – Service in a Workflow 16:53 – 18:42
HashiCorp & Linux Tool Model 18:42 – 19:28
Upgrades 19:28 – 20:09
Immutability 20:09 – 26:35
Compromise for Immutable 26:35 – 32:09
Perfect Fit for Digital Rebar 32:09 – 33:20
3 Requests for DR Project 33:20 – END
Podcast Guest: Will Dennis
Will Dennis is currently employed as a Senior Systems Administrator at NEC Laboratories America, and has over 25 years of experience in managing, installing, and troubleshooting enterprise computing systems, networks, and software. A lifelong learner, Will enjoys keeping current with both tech and culture in the field of Information Technology. Will can be found online on Twitter as @willarddennis, and thru LinkedIn at https://www.linkedin.com/in/willdennis/





 Instructions to install
Instructions to install