Over the summer, the RackN team took a radical step with our previous Ansible Kubernetes workload install: we broke it into pieces. Why? We wanted to eliminate all “magic happens here” steps in the deployment.
 The result, DR Kompos8, is a faster, leaner, transparent and parallelized installation that allows for pluggable extensions and upgrades (video tour). We also chose the operationally simplest configuration choice: Golang binaries managed by SystemDGolang binaries managed by SystemD.
The result, DR Kompos8, is a faster, leaner, transparent and parallelized installation that allows for pluggable extensions and upgrades (video tour). We also chose the operationally simplest configuration choice: Golang binaries managed by SystemDGolang binaries managed by SystemD.
Why decompose and simplify? Let’s talk about our hard earned ops automation battle scars that let to composability as a core value:
Back in the early OpenStack days, when the project was actually much simpler, we were part of a community writing Chef Cookbooks to install it. These scripts are just a sequence of programmable steps (roles in Ops-speak) that drive the configuration of services on each node in the cluster. There is an ability to find cross-cluster information and lookup local inventory so we were able to inject specific details before the process began. However, once the process started, it was pretty much like starting a dominoes chain. If anything went wrong anywhere in the installation, we had to reset all the dominoes and start over.
Like a dominoes train, it is really fun to watch when it works. Also, like dominoes, it is frustrating to set up and fix. Often we literally were holding our breath during installation hoping that we’d anticipated every variation in the software, hardware and environment. It is no surprise that the first and must critical feature we’d created was a redeploy command.
It turned out the the ability to successfully redeploy was the critical measure for success. We would not consider a deployment complete until we could wipe the systems and rebuild it automatically at least twice.
What made cluster construction so hard? There were a three key things: cross-node dependencies (linking), a lack of service configuration (services) and isolating attribute chains (configuration).
We’ll explore these three reasons in detail for part 2 of this post tomorrow.
Even without the details, it easy to understand that we want to avoid all magic in a deployment.
For scale operations, there should never be a “push and prey” step where we are counting on timing or unknown configuration for it to succeed. Likewise, we need to eliminate “it worked from my desktop” automation too. Those systems are impossible to maintain, share and scale. Composed cluster operations addresses this problem by making work modular, predictable and transparent.

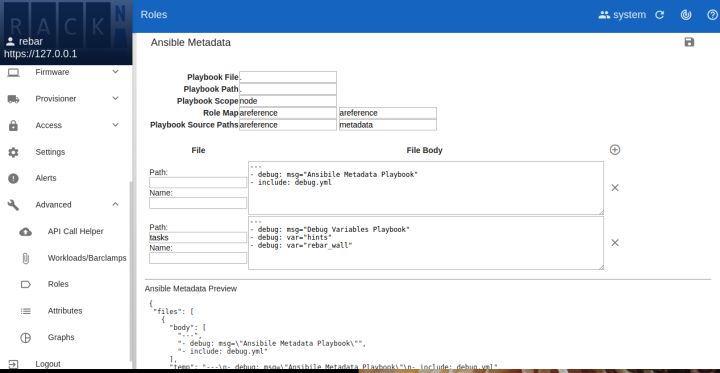
 With our latest patches (short demo videos below), you can now create single role Ansible or Bash scripts dynamically and then incorporate them into the node execution.
With our latest patches (short demo videos below), you can now create single role Ansible or Bash scripts dynamically and then incorporate them into the node execution. Interesting discussions happen when you hang out with straight-talking
Interesting discussions happen when you hang out with straight-talking 

