This week, I have the privilege to showcase the emergence of RackN’s updated approach to data center infrastructure automation that is container-ready and drives “cloud-style” DevOps on physical metal. While it works at scale, we’ve also ensured it’s light enough to run a production-fidelity deployment on a laptop.
This week, I have the privilege to showcase the emergence of RackN’s updated approach to data center infrastructure automation that is container-ready and drives “cloud-style” DevOps on physical metal. While it works at scale, we’ve also ensured it’s light enough to run a production-fidelity deployment on a laptop.
You grow to cloud scale with a ready-state foundation that scales up at every step. That’s exactly what we’re providing with Digital Rebar.
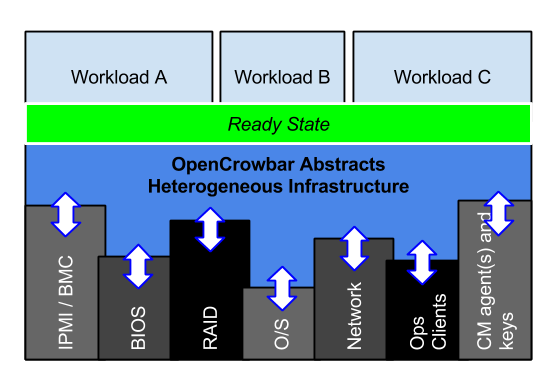
Over the past two years, the RackN team has been working on microservices operations orchestration in the OpenCrowbar code base. By embracing these new tools and architecture, Digital Rebar takes that base into a new directions. Yet, we also get to leverage a scalable heterogeneous provisioner and integrations for all major devops tools. We began with critical data center automation already working.
Why Digital Rebar? Traditional data center ops is being disrupted by container and service architectures and legacy data centers are challenged with gracefully integrating this new way of managing containers at scale: we felt it was time to start a dialog the new foundational layer of scale ops.
Both our code and vision has substantially diverged from the groundbreaking “OpenStack Installer” MVP the RackN team members launched in 2011 from inside Dell and is still winning prizes for SUSE.
We have not regressed our leading vendor-neutral hardware discovery and configuration features; however, today, our discussions are about service wrappers, heterogeneous tooling, immutable container deployments and next generation platforms.
Over the next few days, I’ll be posting more about how Digital Rebar works (plus video demos).

 Want more background on StackEngine?
Want more background on StackEngine?