This post is the third in a 4 part series about Success factors for Operating Open Source Infrastructure.
 In an automated configuration deployment scenario, problems surface very quickly. They prevent deployment and force resolution before progress can be made. Unfortunately, many times this appears to be a failure within the deployment automation. My personal experience has been exactly the opposite: automation creates a “fail fast” environment in which critical issues are discovered and resolved during provisioning instead of sleeping until later.
In an automated configuration deployment scenario, problems surface very quickly. They prevent deployment and force resolution before progress can be made. Unfortunately, many times this appears to be a failure within the deployment automation. My personal experience has been exactly the opposite: automation creates a “fail fast” environment in which critical issues are discovered and resolved during provisioning instead of sleeping until later.
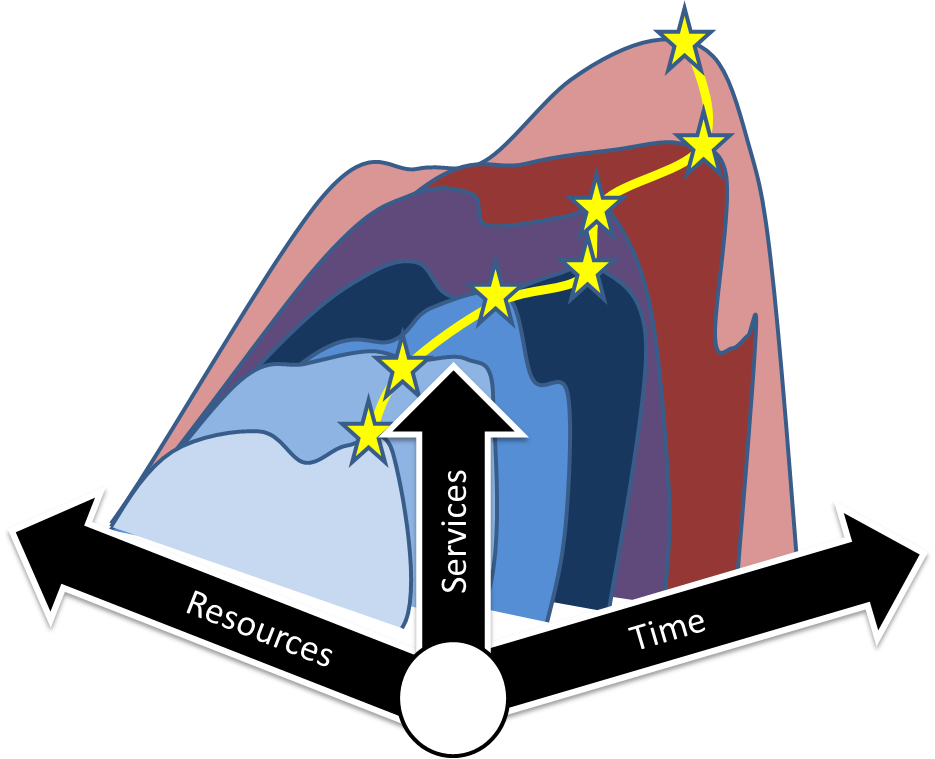
Our ability to detect and stop until these issues are resolved creates exactly the type of repeatable, successful deployment that is essential to long-term success. When we look at these deployments, the most important success factors are that the deployment is consistent, known and predictable. Our ability to quickly identify and resolve issues that do not match those patterns dramatically improves the long-term stability of the system by creating an environment that has been benchmarked against a known reference.
Benchmarking against a known reference is ultimately the most significant value that we can provide in helping customers bring up complex solutions such as Openstack and Hadoop. Being successful with these deployments over the long term means that you have established a known configuration, and that you have maintained it in a way that is explainable and reference-able to other places.
Reference Implementation
The concept of a reference implementation provides tremendous value in deployment. Following a pattern that is a reference implementation enables you to compare notes, get help and ultimately upgrade and change deployment in known, predictable ways. Customers who can follow and implement a vendors’ reference, or the community’s reference implementation, are able to ask for help on the mailing lists, call in for help and work with the community in ways that are consistent and predictable.
Let’s explore what a reference implementation looks like.
In a reference implementation you have a consistent, known state of your physical infrastructure that has been implemented based upon a RA. That implementation follows a known best practice using standard gear in a consistent, known configuration. You can therefore explain your configuration to a community of other developers, or other people who have similar configuration, and can validate that your problem is not the physical configuration. Fundamentally, everything in a reference implementation is driving towards the elimination of possible failure cause. In this case, we are making sure that the physical infrastructure is not causing problems (getting to a ready state), because other people are using a similar (or identical) physical infrastructure configuration.
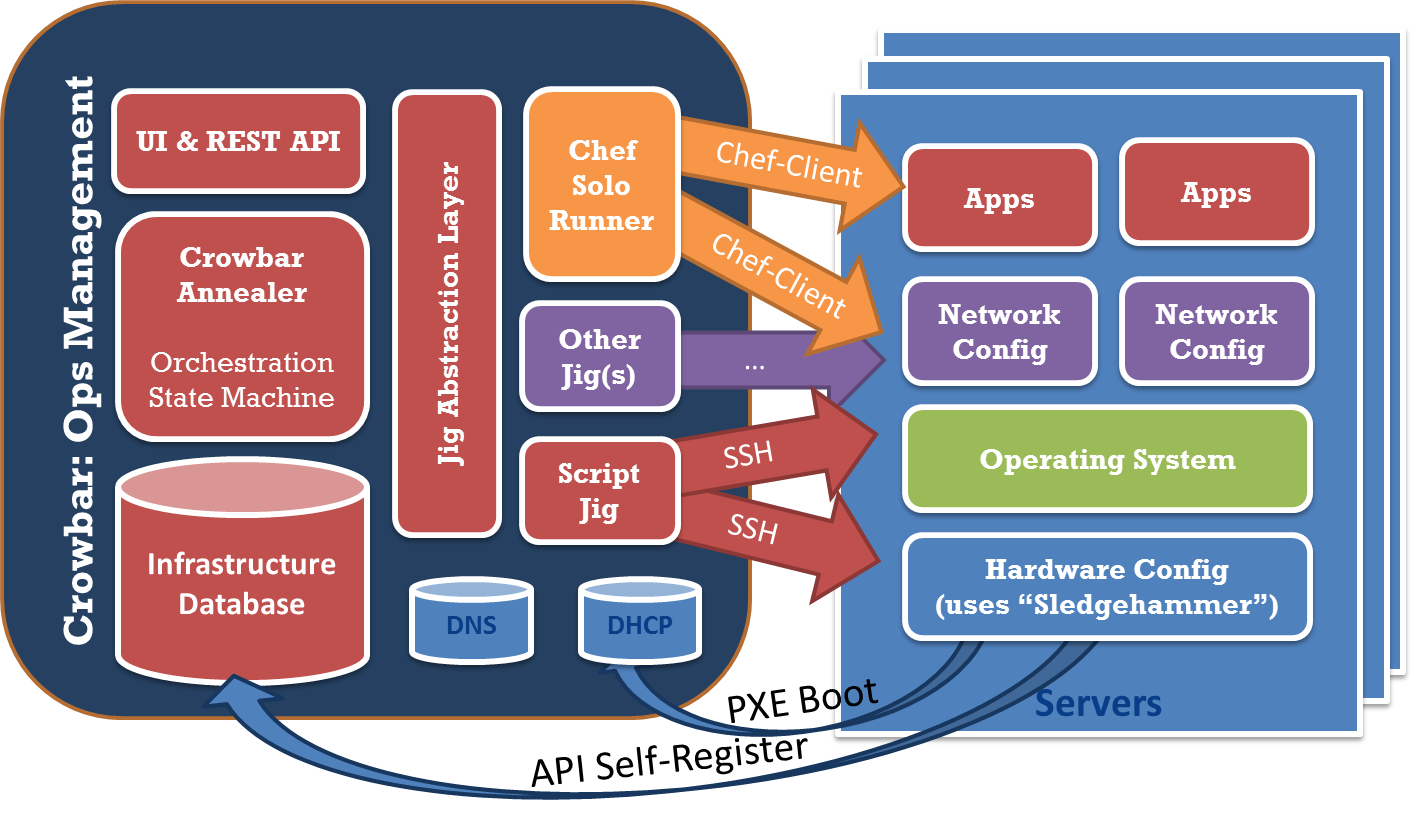
The next components of a reference implementation are the underlying software configurations for operating system management monitoring network configuration, IP networking stacks. Pretty much the entire component of the application is riding on. There are a lot of moving parts and complexity in this scenario, witha high likelihood of causing failures. Implementing and deploying the software stacks in an automated way, has enabled us to dramatically reduce the potential for problems caused by misconfiguration. Because the number of permutations of software in the reference stack is so high, it is essential that successful deployment tightly manages what exactly is deployed, in such a way that they can identify, name, and compare notes with other deployments.
Achieving Repeatable Deployments
In this case, our referenced deployment consists of the exact composition of the operating system, infrastructure tooling, and capabilities for the deployment. By having a reference capability, we can ensure that we have the same:
- Operating system
- Monitoring
- Configuration stacks
- Security tooling
- Patches
- Network stack (including bridges and VLAN, IP table configurations)
Each one of these components is a potential failure point in a deployment. By being able to configure and maintain that configuration automatically, we dramatically increase the opportunities for success by enabling customers to have a consistent configuration between sites.
Repeatable reference deployments enable customers to compare notes with Dell and with others in the community. It enables us to take and apply what we have learned from one site to another. For example, if a new patch breaks functionality, then we can quickly determine how that was caused. We can then fix the solution, add in the complimentary fix, and deploy it at that one site. If we are aware that 90% of our other sites have exactly the same configuration, it enables those other sites to avoid a similar problem. In this way, having both a pattern and practice referenced deployment enables the community to absorb or respond much more quickly, and be successful with a changing code base. We found that it is impractical to expect things not to change.
The only thing that we can do is build resiliency for change into these deployments. Creating an automated and tested referenceable deployment is the best way to cope with change.
 Exploding complexity is pretty easy to grasp when we stack up the number of control elements inside a single server (OS RAID, 2 SSD cache levels, 20 disk JBOD, and UEFI oh dear), the networks that server is connected to, the multi-layer applications installed on the servers, and the change rate of those applications. Multiply that times 100s of servers and we’ve got a problem of unbounded scope even before I throw in SDN overlays.
Exploding complexity is pretty easy to grasp when we stack up the number of control elements inside a single server (OS RAID, 2 SSD cache levels, 20 disk JBOD, and UEFI oh dear), the networks that server is connected to, the multi-layer applications installed on the servers, and the change rate of those applications. Multiply that times 100s of servers and we’ve got a problem of unbounded scope even before I throw in SDN overlays.