OpenStack loves to track developer counts and committers, but velocity without A Feedback loop to set direction is unlikely to get us anywhere sustainable.
 Last week, I attended the first day of the OpenStack Product Working Group meeting. My modest expectations (I just wanted them talking) were far exceeded. The group managed to cover both strategic and tactical items including drafting a charter and discussing pending changes to the incubation process.
Last week, I attended the first day of the OpenStack Product Working Group meeting. My modest expectations (I just wanted them talking) were far exceeded. The group managed to cover both strategic and tactical items including drafting a charter and discussing pending changes to the incubation process.
OpenStack needs a strong feedback loop from users and operators back to developers and vendors – statement made during the PM meeting.
The most critical wins from last week what the desire for the PM group to work more closely with the OpenStack technical leadership. I’m excited to see the community continue to expand the scope of collaboration.
Why is this important? Because developers and product managers need mutual respect to be effective.
The members of the Product team are leaders within their own organization responsible for talking to users and operators. We rely on them to close the communication loop by both collecting feedback and explaining direction. To accomplish this difficult job, the Product team must own articulating a vision for the future.
For OpenStack to succeed, we need to be listening intently to feedback about both how we are doing and if we are headed in the right direction. Both are required to create a feedback loop.
After seeing this group in action, I’m excited to see what’s next.
Want to read more?
Get involved! Join the discussion on the OpenStack Product mailing list!
 ere’s the notice from the
ere’s the notice from the 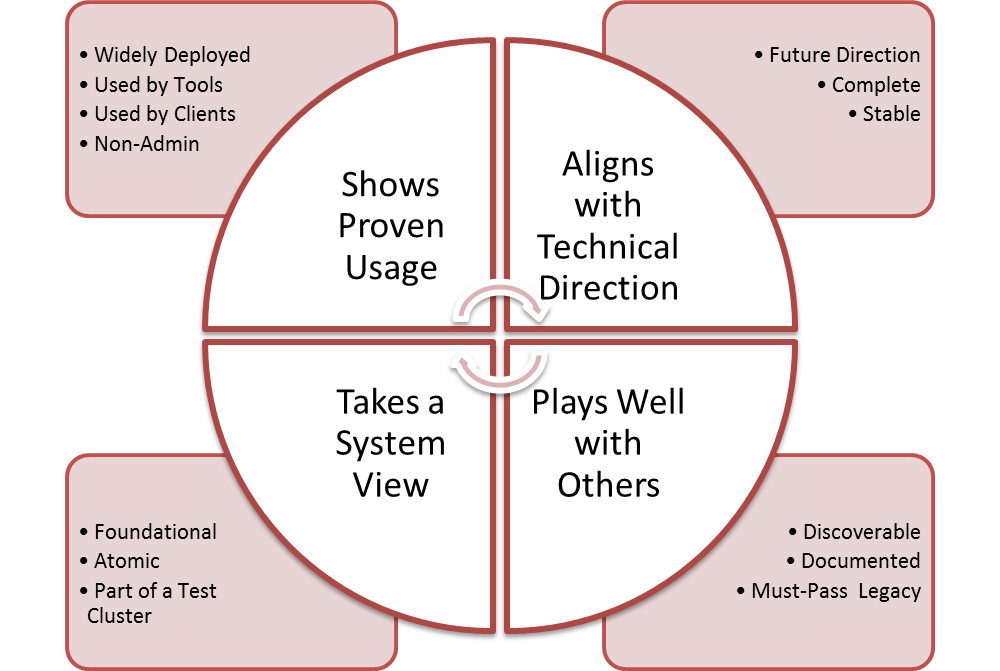


 During last week’s
During last week’s  Last week,
Last week,  Curious about
Curious about 

