THIS POST IS #10 IN A SERIES ABOUT “WHAT IS CORE.”
 We’ve had a number of community discussions (OSCON, SFO & SA-TX) around the process for OpenStack Core definition. These have been animated and engaged discussions (video from SA-TX): my notes for them are below.
We’ve had a number of community discussions (OSCON, SFO & SA-TX) around the process for OpenStack Core definition. These have been animated and engaged discussions (video from SA-TX): my notes for them are below.
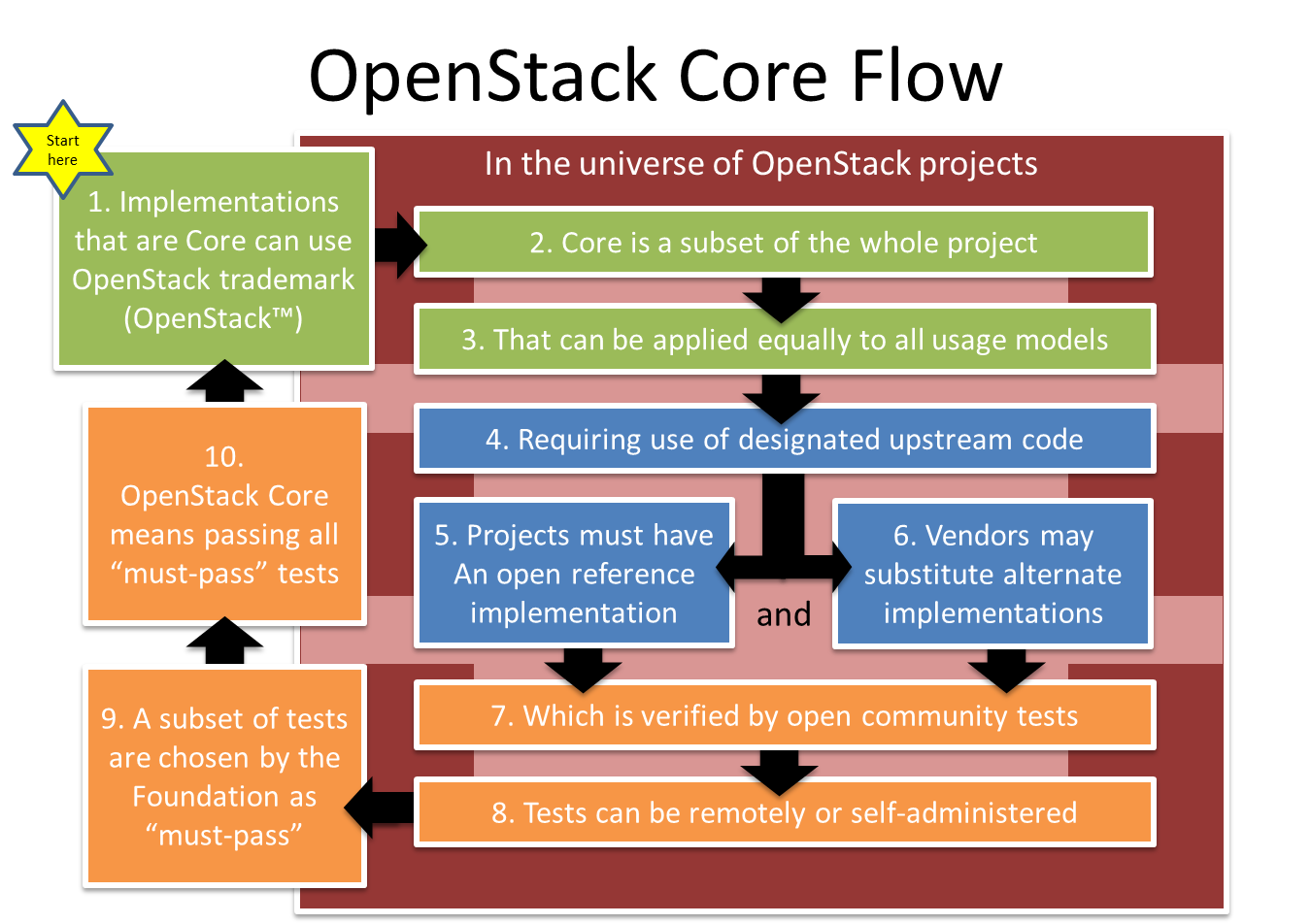
While the current thinking of a testing-based definition of Core adds pressure on expanding our test suite, it seems to pass the community’s fairness checks.
Overall, the discussions lead me to believe that we’re on the right track because the discussions jump from process to impacts. It’s not too late! We’re continuing to get community feedback. So what’s next?
First…. Get involved: Upcoming Community Core Discussions
- 10/8 7pm (Tues) Video from New York City Meetup (Rob Hirschfeld & Monty Taylor)
- 10/16 9am (Wed) Video from Online Meetup (Rob Hirschfeld & Alan Clark)
- 10/22 7pm (Tues) Minnesota Meetup (Kyle Mestery & Sean Roberts)
- Week Before Summit: Beijing Meetup hosted by Alan Clark (details TBD)
These discussions are expected to have online access via Google Hangout. Watch Twitter when the event starts for a link.
Want to to discuss this in your meetup? Reach out to me or someone on the Board and we’ll be happy to find a way to connect with your local community!
What’s Next? Implementation!
So far, the Core discussion has been about defining the process that we’ll use to determine what is core. Assuming we move forward, the next step is to implement that process by selecting which tests are “must pass.” That means we have to both figure out how to pick the tests and do the actual work of picking them. I suspect we’ll also find testing gaps that will have developers scrambling in Ice House.
Here’s the possible (aggressive) timeline for implementation:
- November: Approval of approach & timeline at next Board Meeting
- January: Publish Timeline for Roll out (ideally, have usable definition for Havana)
- March: Identify Havana must pass Tests (process to be determined)
- April: Integration w/ OpenStack Foundation infrastructure
Obviously, there are a lot of details to work out! I expect that we’ll have an interim process to select must-pass tests before we can have a full community driven methodology.
Notes from Previous Discussions (earlier notes):
- There is still confusion around the idea that OpenStack Core requires using some of the project code. This requirement helps ensure that people claiming to be OpenStack core have a reason to contribute, not just replicate the APIs.
- It’s easy to overlook that we’re trying to define a process for defining core, not core itself. We have spent a lot of time testing how individual projects may be effected based on possible outcomes. In the end, we’ll need actual data.
- There are some clear anti-goals in the process that we are not ready to discuss but will clearly going to become issues quickly. They are:
- Using the OpenStack name for projects that pass the API tests but don’t implement any OpenStack code. (e.g.: an OpenStack Compatible mark)
- Having speciality testing sets for flavors of OpenStack that are different than core. (e.g.: OpenStack for Hosters, OpenStack Private Cloud, etc)
- We need to be prepared that the list of “must pass” tests identifies a smaller core than is currently defined. It’s possible that some projects will no longer be “core”
- The idea that we’re going to use real data to recommend tests as must-pass is positive; however, the time it takes to collect the data may be frustrating.
- People love to lobby for their favorite projects. Gaps in testing may create problems.
- We are about to put a lot of pressure on the testing efforts and that will require more investment and leadership from the Foundation.
- Some people are not comfortable with self-reporting test compliance. Overall, market pressure was considered enough to punish cheaters.
- There is a perceived risk of confusion as we migrate between versions. OpenStack Core for Havana seems to specific but there is concern that vendors may pass in one release and then skip re-certification. Once again, market pressure seems to be an adequate answer.
- It’s not clear if a project with only 1 must-pass test is a core project. Likely, it would be considered core. Ultimately, people seem to expect that the tests will define core instead of the project boundary.
What do you think? I’d like to hear your opinions on this!