 There’s no point in sugar-coating this: selecting API and code sections for core requires making hard choices and saying no. DefCore makes this fair by 1) defining principles for selection, 2) going slooooowly to limit surprises and 3) being transparent in operation. When you’re telling someone who their baby is not handsome enough you’d better be able to explain why.
There’s no point in sugar-coating this: selecting API and code sections for core requires making hard choices and saying no. DefCore makes this fair by 1) defining principles for selection, 2) going slooooowly to limit surprises and 3) being transparent in operation. When you’re telling someone who their baby is not handsome enough you’d better be able to explain why.
The truth is that from DefCore’s perspective, all babies are ugly. If we are seeking stability and interoperability, then we’re looking for adults not babies or adolescents.
Explaining why is exactly what DefCore does by defining criteria and principles for our decisions. When we do it right, it also drives a positive feedback loop in the community because the purpose of designated sections is to give clear guidance to commercial contributors where we expect them to be contributing upstream. By making this code required for Core, we are incenting OpenStack vendors to collaborate on the features and quality of these sections.
This does not lessen the undesignated sections! Contributions in those areas are vital to innovation; however, they are, by design, more dynamic, specialized or single vendor than the designated areas.
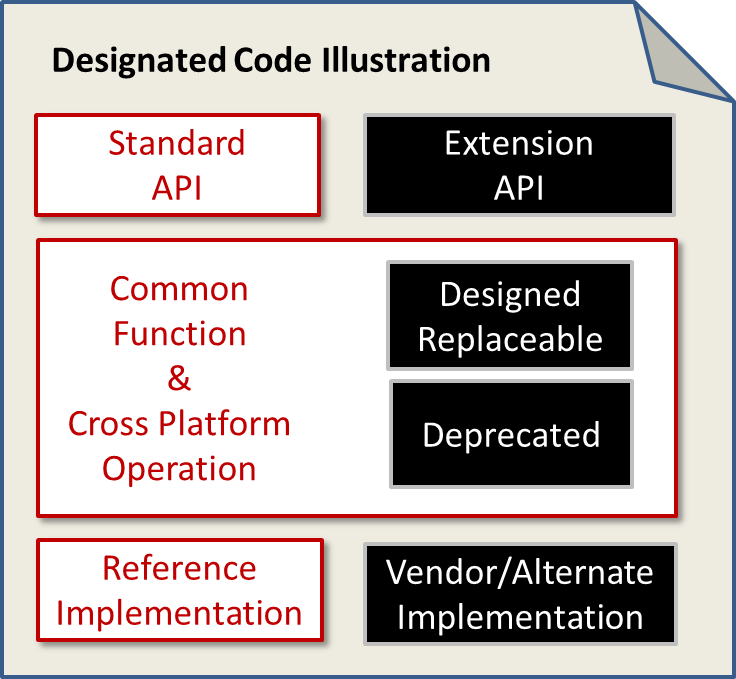 The seven principles of designated sections (see my post with TC member Michael Still) as defined by the Technical Committee are:
The seven principles of designated sections (see my post with TC member Michael Still) as defined by the Technical Committee are:
Should be DESIGNATED:
- code provides the project external REST API, or
- code is shared and provides common functionality for all options, or
- code implements logic that is critical for cross-platform operation
Should NOT be DESIGNATED:
- code interfaces to vendor-specific functions, or
- project design explicitly intended this section to be replaceable, or
- code extends the project external REST API in a new or different way, or
- code is being deprecated
While the seven principles inform our choices, DefCore needs some clarifications to ensure we can complete the work in a timely, fair and practical way. Here are our additions:
8. UNdesignated by Default
- Unless code is designated, it is assumed to be undesignated.
- This aligns with the Apache license.
- We have a preference for smaller core.
9. Designated by Consensus
- If the community cannot reach a consensus about designation then it is considered undesignated.
- Time to reach consensus will be short: days, not months
- Except obvious trolling, this prevents endless wrangling.
- If there’s a difference of opinion then the safe choice is undesignated.
10. Designated is Guidance
- Loose descriptions of designated sections are acceptable.
- The goal is guidance on where we want upstream contributions not a code inspection police state.
- Guidance will be revised per release as part of the DefCore process.
In my next DefCore post, I’ll review how these 10 principles are applied to the Havana release that is going through community review before Board approval.



 I’m certain that the
I’m certain that the  This post is part of a world wide “
This post is part of a world wide “


 When Greg Althaus and I first proposed the project that would become
When Greg Althaus and I first proposed the project that would become 
