I strive to stay neutral as OpenStack DefCore co-chair; however, as someone asking for another Board term, it’s important to review my thinking so that you can make an informed voting decision.
DefCore, while always on the edge of controversy, recently became ground zero for the “what is OpenStack” debate [discussion write up]. My preferred small core “it’s an IaaS product” answer is only one side. Others favor “it’s an open cloud community” while another faction champions an “open cloud platform.” I’m struggling to find a way that it can be all together at the same time.
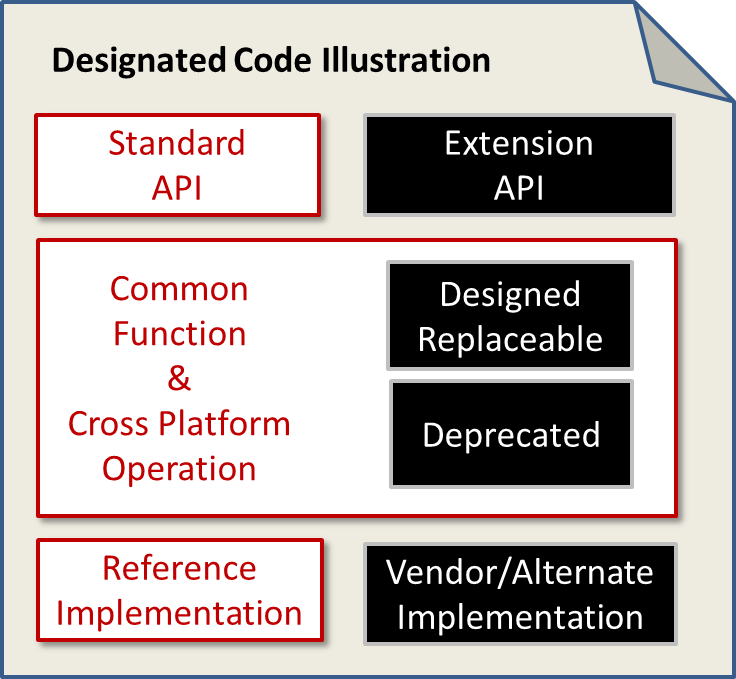
The TL;DR is that, today, OpenStack vendors are required to implement a system that can run Linux guests. This is an example of an implementation over API bias because there’s nothing in the API that drives that specific requirement.
From a pragmatic “get it done” perspective, OpenStack needs to remain implementation driven for now. That means that we care that “OpenStack” clouds run VMs.
While there are pragmatic reasons for this, I think that long term success will require OpenStack to become an API specification. So today’s “right answer” actually undermines the long term community value. This has been a long standing paradox in OpenStack.
Breaking the API to implementation link allows an ecosystem to grow with truly alternate implementations (not just plug-ins). This is a threat to the community “upstream first” mentality. OpenStack needs to be confident enough in the quality and utility of the shared code base that it can allow competitive implementations. Open communities should not need walls to win but they do need clear API definition.
What is my posture for this specific issue? It’s complicated.
First, I think that the user and ecosystem expectations are being largely ignored in these discussions. Many of the controversial items here are vendor initiatives, not user needs. Right now, I’ve heard clearly that those expectations are for OpenStack to be an IaaS the runs VMs. OpenStack really needs to focus on delivering a reliably operable VM based IaaS experience. Until that’s solid, the other efforts are vendor noise.
Second, I think that there are serious test gaps that jeopardize the standard. The fundamental premise of DefCore is that we can use the development tests for API and behavior validation. We chose this path instead of creating an independent test suite. We either need to address tests for interop within the current body of tests or discuss splitting the efforts. Both require more investment than we’ve been willing to make.
We have mechanisms in place to collects data from test results and expand the test base. Instead of creating new rules or guidelines, I think we can work within the current framework.
The simple answer would be to block non-VM implementations; however, I trust that cloud consumers will make good decisions when given sufficient information. I think we need to fix the tests and accept non-VM clouds if they pass the corrected tests.
For this and other reasons, I want OpenStack vendors to be specific about the configurations that they test and support. We took steps to address this in DefCore last year but pulled back from being specific about requirements. In this particular case, I believe we should require the official OpenStack vendor to state clear details about their supported implementation. Customers will continue vote with their wallet about which configuration details are important.
This is a complex issue and we need community input. That means that we need to hear from you! Here’s the TC Position and the DefCore Patch.