I was interviewed about DefCore by Jason Baker of Red Hat as part of my participation in OSCON Open Cloud Day (speaking Monday 11:30am). This is just one of fifteen in a series of speaker interviews covering everything from Docker to Girls in Tech.
I was interviewed about DefCore by Jason Baker of Red Hat as part of my participation in OSCON Open Cloud Day (speaking Monday 11:30am). This is just one of fifteen in a series of speaker interviews covering everything from Docker to Girls in Tech.
This interview serves as a good review of DefCore so I’m reposting it here:
Without giving away too much, what are you discussing at OSCON? What drove the need for DefCore?
I’m going to walk through the impact of the OpenStack DefCore process in real terms for users and operators. I’ll talk about how the process works and how we hope it will make OpenStack users’ lives better. Our goal is to take steps towards interoperability between clouds.
DefCore grew out of a need to answer hard and high stakes questions around OpenStack. Questions like “is Swift required?” and “which parts of OpenStack do I have to ship?” have very serious implications for the OpenStack ecosystem.
It was impossible to reach consensus about these questions in regular board meetings so DefCore stepped back to base principles. We’ve been building up a process that helps us make decisions in a transparent way. That’s very important in an open source community because contributors and users want ground rules for engagement.
It seems like there has been a lot of discussion over the OpenStack listservs over what DefCore is and what it isn’t. What’s your definition?
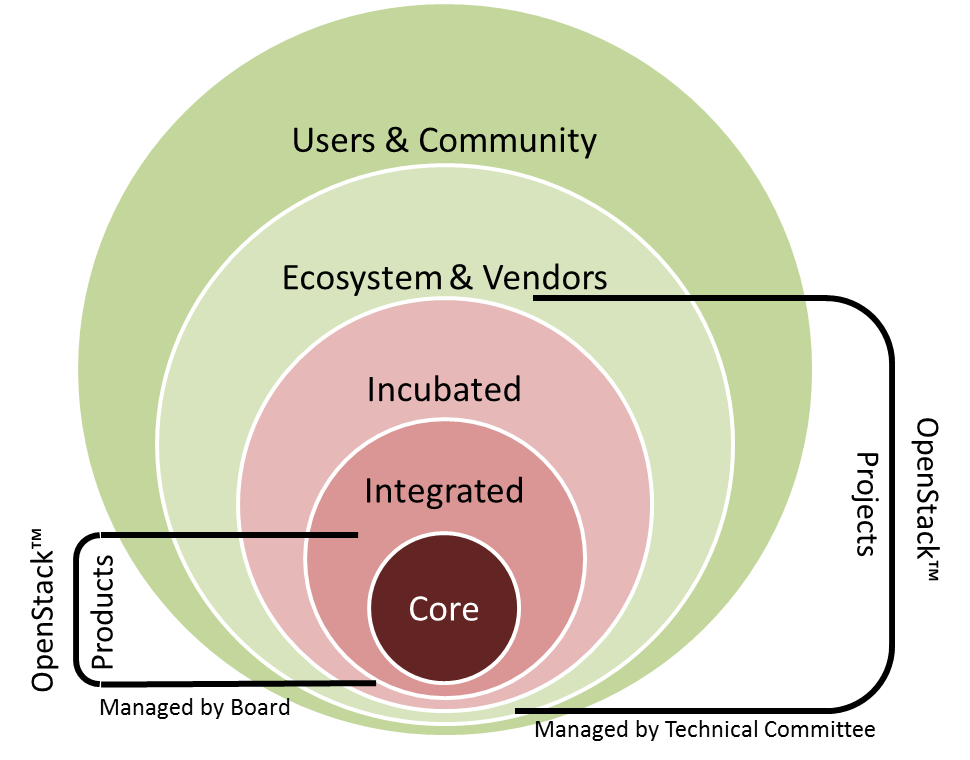
First, DefCore applies only to commercial uses of the OpenStack name. There are different rules for the integrated code base and community activity. That’s the place of most confusion.
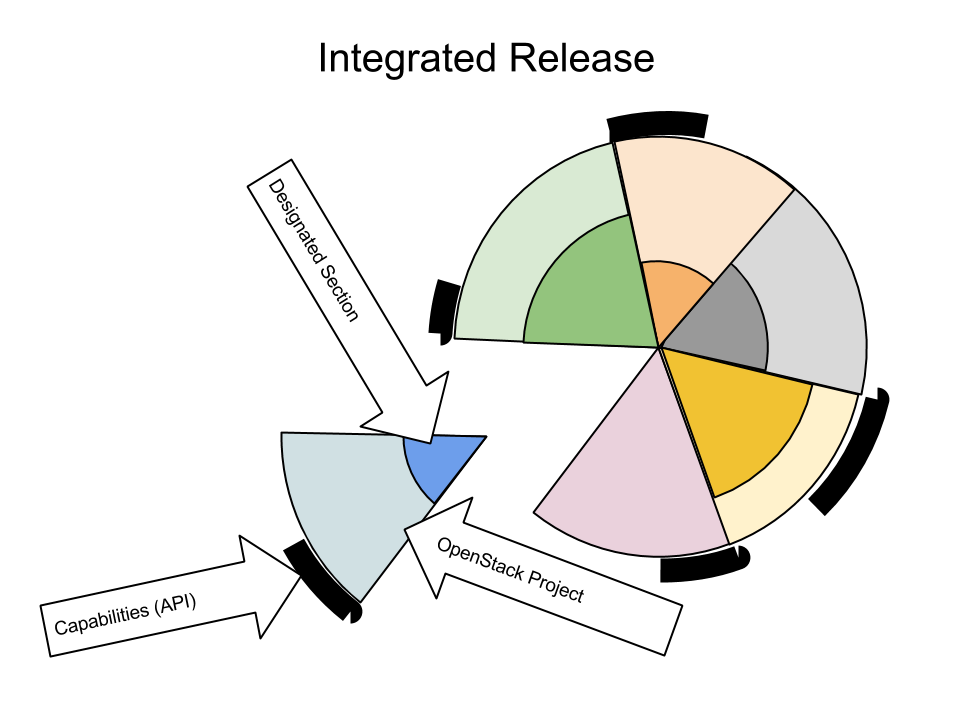
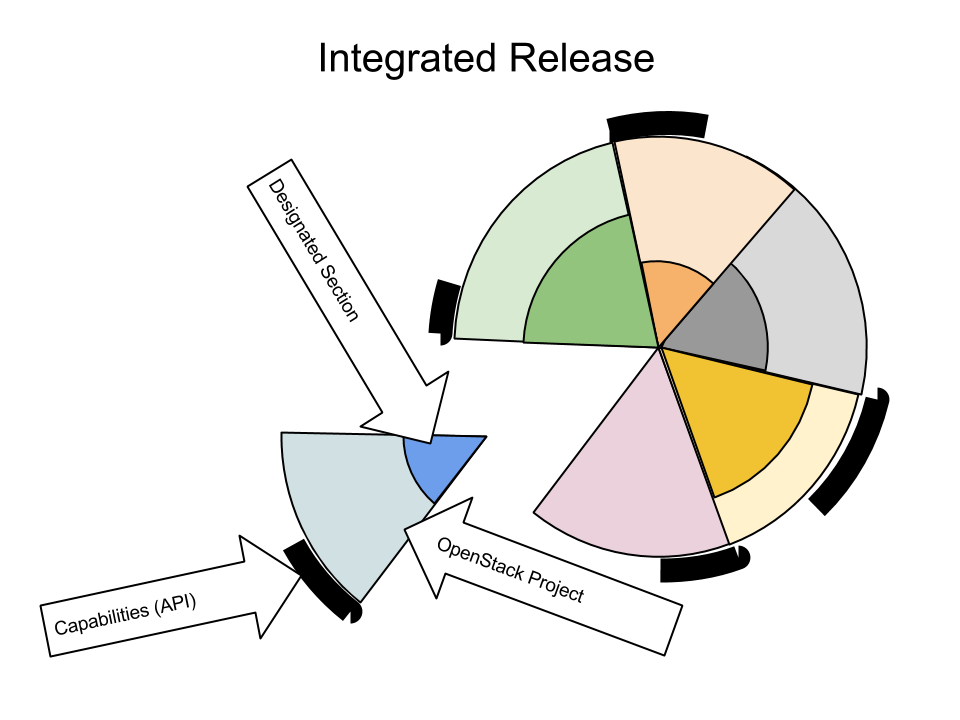
Basically, DefCore establishes the required minimum feature set for OpenStack products.
The longer version includes that it’s a board managed process that’s designed to be very transparent and objective. The long-term objective is to ensure that OpenStack clouds are interoperable in a measurable way and that we also encourage our vendor ecosystem to keep participating in upstream development and creation of tests.
A final important component of DefCore is that we are defending the OpenStack brand. While we want a vibrant ecosystem of vendors, we must first have a community that knows what OpenStack is and trusts that companies using our brand comply with a meaningful baseline.
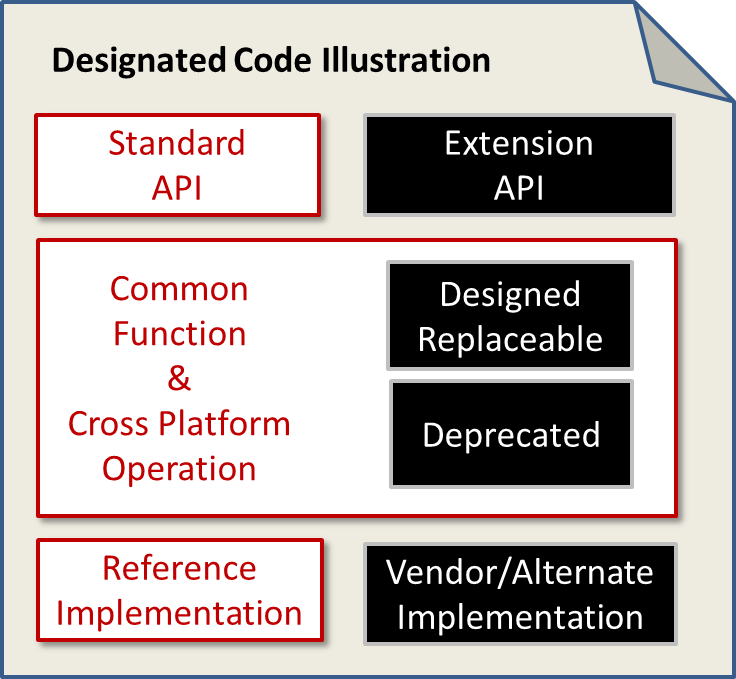
Are there other open source projects out there using “designated sections” of code to define their product, or is this concept unique to OpenStack? What lessons do you think can be learned from other projects’ control (or lack thereof) of what must be included to retain the use of the project’s name?
I’m not aware of other projects using those exact words. We picked up ‘designated sections’ because the community felt that ‘plug-ins’ and ‘modules’ were too limited and generic. I think the term can be confusing, but it was the best we found.
If you consider designated sections to be plug-ins or modules, then there are other projects with similar concepts. Many successful open source projects (Eclipse, Linux, Samba) are functionally frameworks that have very robust extensibility. These projects encourage people to use their code base creatively and then give back some (not all) of their lessons learned in the form of code contributes. If the scope returning value to upstream is too broad then sharing back can become onerous and forking ensues.
All projects must work to find the right balance between collaborative areas (which have community overhead to join) and independent modules (which allow small teams to move quickly). From that perspective, I think the concept is very aligned with good engineering design principles.
The key goal is to help the technical and vendor communities know where it’s safe to offer alternatives and where they are expected to work in the upstream. In my opinion, designated sections foster innovation because they allow people to try new ideas and to target specialized use cases without having to fight about which parts get upstreamed.
What is it like to serve as a community elected OpenStack board member? Are there interests you hope to serve that are difference from the corporate board spots, or is that distinction even noticeable in practice?
It’s been like trying to row a dragon boat down class III rapids. There are a lot of people with oars in the water but we’re neither all rowing together nor able to fight the current. I do think the community members represent different interests than the sponsored seats but I also think the TC/board seats are different too. Each board member brings a distinct perspective based on their experience and interests. While those perspectives are shaped by their employment, I’m very happy to say that I do not see their corporate affiliation as a factor in their actions or decisions. I can think of specific cases where I’ve seen the opposite: board members have acted outside of their affiliation.
When you look back at how OpenStack has grown and developed over the past four years, what has been your biggest surprise?
Honestly, I’m surprised about how many wheels we’ve had to re-invent. I don’t know if it’s cultural or truly a need created by the size and scope of the project, but it seems like we’ve had to (re)create things that we could have leveraged.
What are you most excited about for the “K” release of OpenStack?
The addition of platform services like database as a Service, DNS as a Service, Firewall as a Service. I think these IaaS “adjacent” services are essential to completing the cloud infrastructure story.
Any final thoughts?
In DefCore, we’ve moved slowly and deliberately to ensure people have a chance to participate. We’ve also pushed some problems into the future so that we could resolve the central issues first. We need to community to speak up (either for or against) in order for us to accelerate: silence means we must pause for more input.