I’m working on my OpenStack summit talk about DevOps upgrade patterns and got to a point where there are three major vectors to consider:
- Step Size (shown as X axis): do we make upgrades in small frequent steps or queue up changes into larger bundles? Larger steps mean that there are more changes to be accommodated simultaneously.
- Change Leader (shown as Y axis): do we upgrade the server or the client first? Regardless of the choice, the followers should be able to handle multiple protocol versions if we are going to have any hope of a reasonable upgrade.
- Safeness (shown as Z axis): do the changes preserve the data and productivity of the entity being upgraded? It is simpler to assume to we simply add new components and remove old components; this approach carries significant risks or redundancy requirements.
I’m strongly biased towards continuous deployment because I think it reduces risk and increases agility; however, I laying out all the vertices of the upgrade cube help to visualize where the costs and risks are being added into the traditional upgrade models.
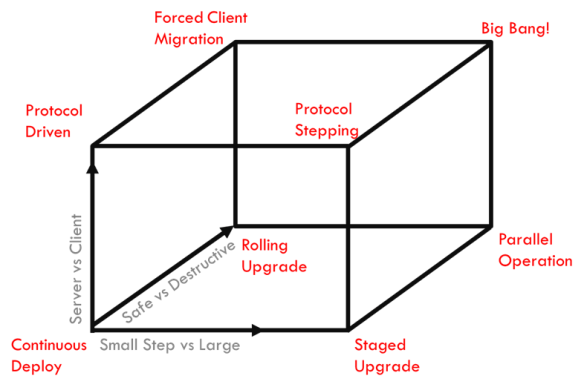
Breaking down each vertex:
- Continuous Deploy – core infrastructure is updated on a regular (usually daily or faster) basis
- Protocol Driven – like changing to HTML5, the clients are tolerant to multiple protocols and changes take a long time to roll out
- Staged Upgrade – tightly coordinate migration between major versions over a short period of time in which all of the components in the system step from one version to the next together.
- Rolling Upgrade – system operates a small band of versions simultaneously where the components with the oldest versions are in process of being removed and their capacity replaced with new nodes using the latest versions.
- Parallel Operation – two server systems operate and clients choose when to migrate to the latest version.
- Protocol Stepping – rollout of clients that support multiple versions and then upgrade the server infrastructure only after all clients have achieved can support both versions.
- Forced Client Migration – change the server infrastructure and then force the clients to upgrade before they can reconnect.
- Big Bang – you have to shut down all components of the system to upgrade it
This type of visualization helps me identify costs and options. It’s not likely to get much time in the final presentation so I’m hoping to hear in advance if it resonates with others.
PS: like this visualization? check out my “magic 8 cube” for cloud hosting options.

I’m not clear on what protocol-driven would look like procedurally, but it’s a useful visual…
LikeLike
My thought on that is that it would be like the HTML version migrations where your have to distribute clients that support the new protocol before you can start the server migration or have to negotiate protocol version as part of connection. It’s a much slower path but very friendly for a massively distributed system.
LikeLike
Excellent tool for comparison, Rob. However, I think you often over-emphasize the role of the client, especially in parallel operation. I’ve done plenty of parallel operational migrations where the service chooses the path and not the client. It’s a very important factor for continuous deployment, as well. Having the entire service determine which users and/or clients use which features and/or versions of the service is a key application design pattern that leads to tremendous velocity.
LikeLike
It is a good model for simplifying and potentially costing the architectural implementation decisions; however, there are a large number of other factors that may need to be taken into consideration — ranging from end user issues: performance expectations (in the broader context), efficiency expectations, and the impact of change on continued-use scenarios — to organisational culture issues: social influence, reputational protection, etc. So in reality, the “cube” is probably better represented by a Schlegel diagram http://en.wikipedia.org/wiki/File:Tesseract.gif
Keep up the good work! And “hi” from NZ!
LikeLike
Totally agree the there are more dimensions. I get glassy eyed looks from 3, so I can’t imagine more factors.
Great to hear from you Matt!! How are Ruth and the kiddos doing?
LikeLike
Good points. I think I’m using client in multiple ways since I classify the nova compute agent as a client in addition to the cloud end user too. Need a word for that, but not a fan of agent or slave.
LikeLike
Pingback: OpenStack’s next hurdle: Interoperability. Why should you care? | Rob Hirschfeld's Blog
Pingback: Dell Open Source Ecosystem Digest #15. Issue Highlights: "Interviews with SUSE, Cisco and Cloudscaling" - Dell TechCenter - TechCenter - Dell Community
Pingback: Dell Open Source Ecosystem Digest #15. Issue Highlights: "Interviews with SUSE, Cisco and Cloudscaling" (englischsprachig) - TechCenter - Blog - TechCenter – Dell Community
Pingback: Recap of Day 1 at OpenStack Summit- Sessions and Ecosystem Interviews - #DellSolves - #DellSolves - Dell Community
Pingback: Dell Community
Pingback: OpenStack Day #1 Recap - Dell TechCenter - TechCenter - Dell Community
Pingback: OpenStack Summit Day #1 Recap | ServerGround.net
Pingback: Server King » Dell’s Digest for April 16, 2013