I’m working on my OpenStack summit talk about DevOps upgrade patterns and got to a point where there are three major vectors to consider:
- Step Size (shown as X axis): do we make upgrades in small frequent steps or queue up changes into larger bundles? Larger steps mean that there are more changes to be accommodated simultaneously.
- Change Leader (shown as Y axis): do we upgrade the server or the client first? Regardless of the choice, the followers should be able to handle multiple protocol versions if we are going to have any hope of a reasonable upgrade.
- Safeness (shown as Z axis): do the changes preserve the data and productivity of the entity being upgraded? It is simpler to assume to we simply add new components and remove old components; this approach carries significant risks or redundancy requirements.
I’m strongly biased towards continuous deployment because I think it reduces risk and increases agility; however, I laying out all the vertices of the upgrade cube help to visualize where the costs and risks are being added into the traditional upgrade models.
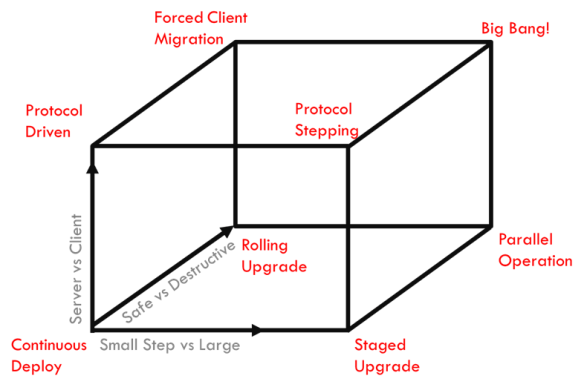
Breaking down each vertex:
- Continuous Deploy – core infrastructure is updated on a regular (usually daily or faster) basis
- Protocol Driven – like changing to HTML5, the clients are tolerant to multiple protocols and changes take a long time to roll out
- Staged Upgrade – tightly coordinate migration between major versions over a short period of time in which all of the components in the system step from one version to the next together.
- Rolling Upgrade – system operates a small band of versions simultaneously where the components with the oldest versions are in process of being removed and their capacity replaced with new nodes using the latest versions.
- Parallel Operation – two server systems operate and clients choose when to migrate to the latest version.
- Protocol Stepping – rollout of clients that support multiple versions and then upgrade the server infrastructure only after all clients have achieved can support both versions.
- Forced Client Migration – change the server infrastructure and then force the clients to upgrade before they can reconnect.
- Big Bang – you have to shut down all components of the system to upgrade it
This type of visualization helps me identify costs and options. It’s not likely to get much time in the final presentation so I’m hoping to hear in advance if it resonates with others.
PS: like this visualization? check out my “magic 8 cube” for cloud hosting options.
