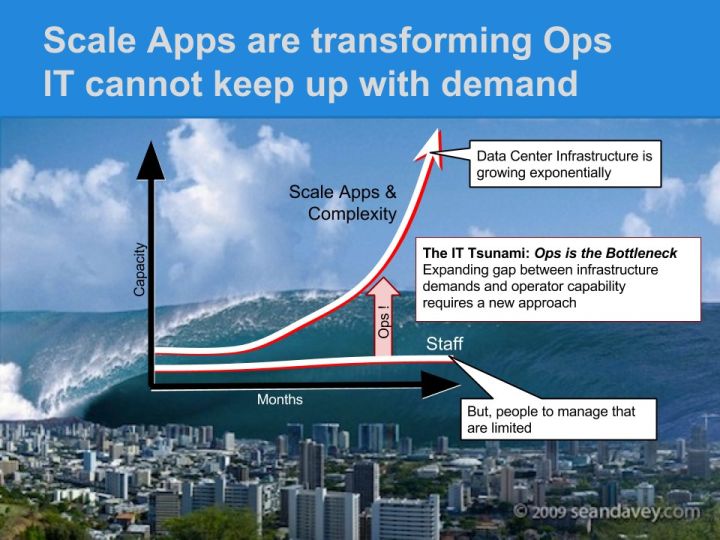
Our focus on SRE series continues… At RackN, we see a coming infrastructure explosion in both complexity and scale. Unless our industry radically rethinks operational processes, current backlogs will escalate and stability, security and sharing will suffer.
Our focus on SRE series continues… At RackN, we see a coming infrastructure explosion in both complexity and scale. Unless our industry radically rethinks operational processes, current backlogs will escalate and stability, security and sharing will suffer.
SRE minded teams are very impatient about eliminating manual, routine and non-differentiated work.
I’ve been talking to a lot of people about SRE lately in the context of helping Ops get out of the way while coping with increasing load and complexity. Why are they so impatient? Because they know that ops demand is constantly increasing, there’s no “good enough” when it comes to finding ways to automate tasks and move up stack. Without consistent improvement in automation, teams will get buried (my post about Ops Debt).
The core SRE mantra needs to be “Own Ops, don’t be owned by Ops.”
Yet, outsourcing ops responsibility to a service is equally problematic for an SRE. They cannot give up responsibility for the integrated system. In fact, that’s one of the basic reasons why Google’s SRE teams went from just “web site reliability” to full system thinking. Every aspect of the infrastructure stack needs to be considered when looking at system performance and reliability. For example, something deep like SSD drive write behavior or GPU BIOS could make a critical difference. SREs need to be able to root cause issues and black box infrastructure (a.k.a. Cloud) can get in the way.
SRE teams must balance owning the full stack versus focusing on what makes their job unique.
That’s why we have been rethinking about how SRE teams approach infrastructure. Instead of trying to turn infrastructure into a black box services; we’ve designed the Digital Rebar composable Ops platform that embraces and contains heterogeneity with a high degree of transparency and control. This is critical because SREs cannot afford to keep reinventing automation at the bottom of the stack. We must be able to share and leverage best-practices on infrastructure provisioning and platform deployment.
Like the hardware that runs it, the foundation automation layer must be commoditized.
That means that Operators should be able to buy infrastructure (physical and cloud) from any vendor and run it in a consistent way. Instead of days or weeks to get infrastructure running, it should take hours and be fully automated from power-on. We should be able to rehearse on cloud and transfer that automation directly to (and from) physical without modification. That practice and pace should be the norm instead of the exception.
That’s what we are building at RackN. Our primary goal is to reuse automation whenever possible. That was our top design priority for Digital Rebar and it drives our customer engagement models. If you’d like to hear more, download our SRE white paper.
More information:
- RackN Home Page
- RackN YouTube Page – See our technology in action
- Contact Us: sre@RackN.com