By Dan Choquette
Is DevOps at scale like a major city’s subway system? Both require strict processes and operational excellence to move a lot of different parts at once. How else?
If you had the pleasure of riding the Tokyo Metro, you might agree that it’s an interesting – and confusing experience (especially if you need to change lines!) All totaled, there are 9 lines, roughly 180+ stations with a daily ridership of almost 7 million people!

A few days ago, I had a conversation with a potential user deploying Kubernetes with Contrail networking on Google Cloud repeatedly in a build/test/dev scenario. The other conversation was around the need to provision thousands of x86 bare metal servers once to twice a week with different configurations and networking with the need to ultimately control their metal as they would a cloud instance in AWS. Cool stuff!
Since we here at RackN believe Hybrid DevOps is a MUST for Hybrid IT (after all, we are a start-up and have bet our very lives on such a thing so we REALLY believe it!) I thought about how Hybrid DevOps compares to the Tokyo Metro (earlier that day I read about Tokyo in the news and the mind wandered). In my attempt to draw the parallel, below is an SDLC DevOps framework that you have seen 233 times before in blogs like this one.

In terms of process, I’m sure you can notice how similar it is to the Metro, right?
<crickets>
<more crickets>
When both operate as they should, they are the epitome of automation, control, repeat-ability and reliability. In disciplined, automated at-scale DevOps environments it does have some similarity to the Ginza or Tozai line. You have different people (think apps) of all walks of life boarding a train needing to get somewhere and need to follow steps in a process (maybe the “Pusher” is the scrum or DevOps governance tool but we’ll leave that determination for the end). However, as I compare it to Hybrid DevOps, the Tokyo Metro is not hybrid-tolerant. With subways, if a new subway car is added, tracks are changed, or a new station is added instantaneously to better handle congestion everything stops or turns into a logistical disaster. In addition, there is no way of testing how it will all flow before hand. There will be operational glitches and millions of angry customers will not reach their destination in a timely fashion- or at all.
The same is metaphorically true for Hybrid DevOps in Hybrid IT. In theory, the Hybrid DevOps pipeline includes build/test/dev and continuous integration/deployment for all platforms, business models, governance models, security and software stacks in which are dependent with the physical/IaaS/container underlay. Developers and operators need to test against multiple platforms (cloud, VM and metal) and in order to realize value, assimilate into production rapidly while at the same time frequently adjusting to changes of all kinds. They also require the ability to layer multiple technologies and security policies into an operational pipeline which in turn has hundreds of moving parts which require precise configuration settings to be made in a sequenced, orchestrated manner.
At RackN, in order to continuously test, integrate, deploy and manage complex technologies in a Hybrid IT scenario is critical to a successful adoption in production. The most optimal way to accomplish that is to have in place a central platform than can govern Hybrid DevOps at scale that can automate, orchestrate and compose allthe necessary configurations and components in a sequenced fashion. Without one, hap-hazard assembly and lack of governance erodes the overall process and leads to failure. Just like the “Pusher” on the platform, without governance both the Tokyo Metro and a Hybrid DevOps model at scale being used for a Hybrid IT use case leads to massive delays, dissatisfied customers and chaos.



 If you get an F4-E1 (washer pump bad) code, then you MUST clear the code after you replace the drive motor. The reset code is pressing any three bottons in a 1-2-3 sequence three times (so 1-2-3, 1-2-3, 1-2-3). I took a picture of my unit with all lights on after I entered the diagnostic code.
If you get an F4-E1 (washer pump bad) code, then you MUST clear the code after you replace the drive motor. The reset code is pressing any three bottons in a 1-2-3 sequence three times (so 1-2-3, 1-2-3, 1-2-3). I took a picture of my unit with all lights on after I entered the diagnostic code.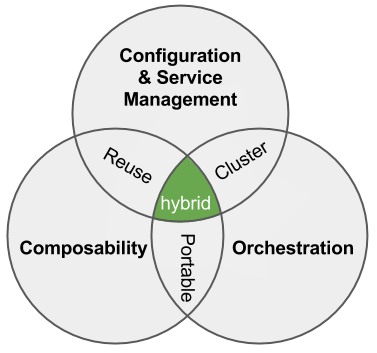 Here’s our write-up:
Here’s our write-up: 

 awareness, you can be more secure WITHOUT putting more work for developers.
awareness, you can be more secure WITHOUT putting more work for developers.
