The first release of the DefCore Core Capabilities Matrix (DCCM) was revealed at the Atlanta summit. At the Summit, Joshua and I had a session which examined what this means for the various members of the OpenStack community. This rather lengthy post reviews the same advisory material.
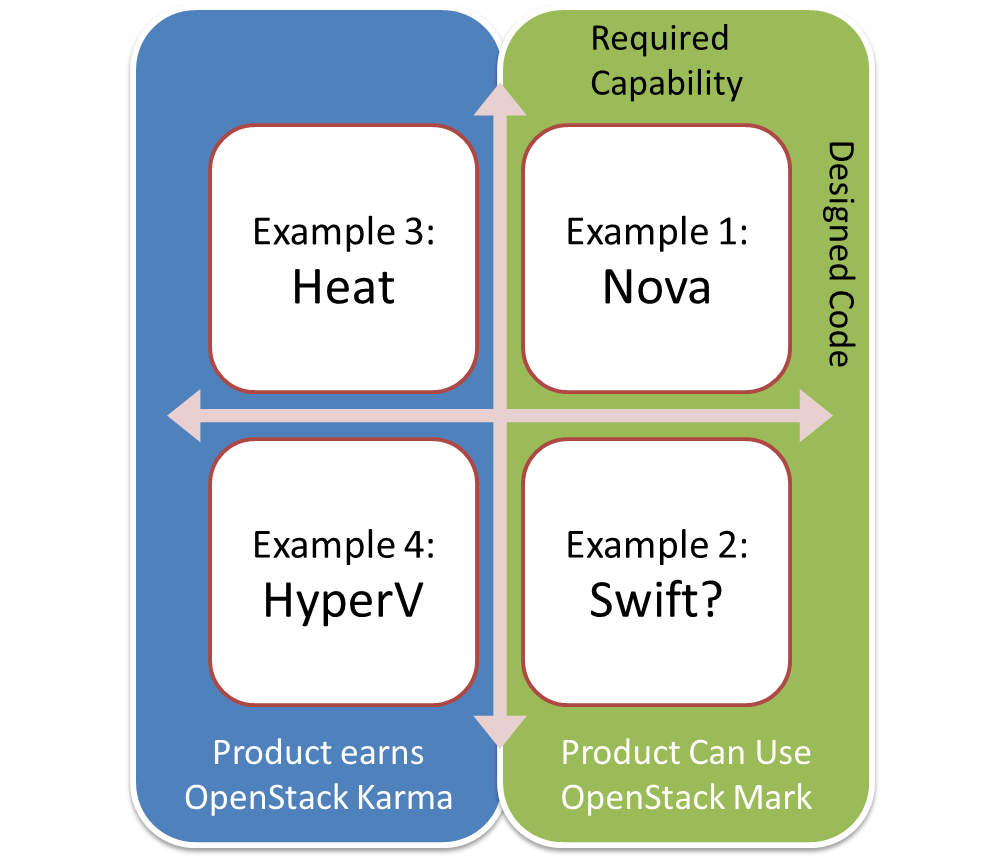
DefCore sets base requirements by defining 1) capabilities, 2) code and 3) must-pass tests for all OpenStack products. This definition uses community resources and involvement to drive interoperability by creating the minimum standards for products labeled “OpenStack.”
As a refresher, there are three uses of the OpenStack mark:
- Community: The non-commercial use of the word OpenStack by the OpenStack community to describe themselves and their activities. (like community tweets, meetups and blog posts)
- Code: The non-commercial use of the word OpenStack to refer to components of the OpenStack framework integrated release (as in OpenStack Compute Project Nova)
- Commerce: The commercial use of the word OpenStack to refer to products and services as governed by the OpenStack trademark policy. This is where DefCore is focused.
In the DefCore/Commerce use, properly licensed vendors have three basic obligations to meet:
- Pass the required Refstack tests for the capabilities matrix in the version of OpenStack that they use. Vendors are expected (not required) to share their results.
- Run and include the “designated sections” of code for the OpenStack components that you include.
- Other basic obligations in their license agreement like being a currently paid up corporate sponsor or foundation member, etc.
If they meet these conditions, vendors can use the OpenStack mark in their product names and descriptions.
Enough preamble! Let’s see the three Advisory Cases
MANDATORY DISCLAIMER: These conditions apply to fictional public, private and client use cases. Any resemblence to actual companies is a function of the need to describe real use-cases. These cases are advisory for illustration use only and are not to be considered definitive guidenance because DefCore is still evolving.
Public Cloud: Service Provider “BananaCloud”
A popular public cloud operator, BananaCloud has been offering OpenStack-based IaaS since the Diablo release. However, they don’t use the Keystone component. Since they also offer traditional colocation and managed services, they have an existing identity management system that they use. They made a similar choice for Horizon in favor of their own cloud portal.

- They use Nova a custom scheduler and pass all the Nova tests. This is the simplest case since they use code and pass the tests.
- In the Havana DCCM, the Keystone capabilities are a must pass test; however, there are no designated sections of code for Keystone. So BananaCloud must implement a Keystone-compatible API on their IaaS environment (an effort they had underway already) that will pass Refstack, and they’re good to go.
- There are no must pass tests for Horizon so they have no requirements to include those features or code. They can still be OpenStack without Horizon.
- There are no must pass tests for Trove so they have no brand requirements to include those features or code so it’s not a brand issue; however, by using Trove and promoting its use, they increase the likelihood of its capabilities becoming must pass features.
BananaCloud also offers some advanced OpenStack capabilities, including Marconi and Trove. Since there are no must pass capabilities from these components in the Havana DCCM, it has no impact on their offering additional services. DefCore defines the minimum requirements and encourages vendors to share their full test results of additional capabilities because that is how OpenStack identifies new must pass candidates.
Note: The DefCore DCCM is advisory for the Havana release, so if BananaCloud is late getting their Keystone-compatibility work done there won’t be any commercial impact. But it will be a binding part of the trademark license agreement by the Juno release, which is only 6 months away.
Private Cloud: SpRocket Small-Business OpenStack Software
SpRocket is a new OpenStack software vendor, specializing in selling a Windows-powered version of OpenStack with tight integration to Sharepoint and AzurePack. In their feature set, they only need part of Nova and provide an alternative object storage to Swift that implements a version of the Swift API. They do use Heat as part of their implementation to set up applications back ended by Sharepoint and AzurePack.
 For Nova, they already use the code and have already implemented all required capabilities except for the key-store. To comply with the DefCore requirement, they must enable the key-store capability.
For Nova, they already use the code and have already implemented all required capabilities except for the key-store. To comply with the DefCore requirement, they must enable the key-store capability.- While their implementation of Swift passes the tests, We are still working to resolve the final disposition of Swift so there are several possible outcomes:
- If Swift is 0% designated then they are OK (that’s illustrated here)
- If Swift is 100% designated then they cannot claim to be OpenStack.
- If Swift is partially designated then they have to adapt their deploy to include the required code.
- Their use of Heat is encouraged since it is an integrated project; however, there are no required capabilities and does not influence their ability to use the mark.
- They use the trunk version of Windows HyperV drivers which are not designated and have no specific tests.
Ecosystem Client: “Mist” OpenStack-consuming Client Library
Mist is a client library for load+kt programmers working on applications using the OpenStack APIs. While it’s an open source project, there are many commercial applications that use the library for their applications. Unlike a “pure” OpenStack program, it also supports other Cloud APIs.
Since the Mist library does not ship or implement the OpenStack code base, the DefCore process does not apply to their effort; however, there are several important intersections with Mist and OpenStack and Core.
- First, it is very important for the DefCore process that Mist map their use of the OpenStack APIs to the capabilities matrix. They are asked to help with this process because they are the best group to answer the “works with clients” criteria.
- Second, if there are APIs used by Mist that are not currently tested then the OpenStack community should work with the Mist community to close those test gaps.
- Third, if Mist relies on an API that is not must-pass they are encouraged to help identify those capabilities as core candidates in the community.