Ceph in an hour? Boring! How about Ceph hardware optimized with advanced topology networking & IPv6?
2
For the Paris summit, the OpenCrowbar team delivered a PackStack demo that leveraged Crowbar’s ability to create a OpenStack ready state environment. For the Vancouver summit, we did something even bigger: we updated the OpenCrowbar Ceph workload.
C eph is the leading open source block storage back-end for OpenStack; however, it’s tricky to install and few vendors invest the effort to hardware optimize their configuration. Like any foundation layer, configuration or performance errors in the storage layer will impact the entire system. Further, the Ceph infrastructure needs to be built before OpenStack is installed.
eph is the leading open source block storage back-end for OpenStack; however, it’s tricky to install and few vendors invest the effort to hardware optimize their configuration. Like any foundation layer, configuration or performance errors in the storage layer will impact the entire system. Further, the Ceph infrastructure needs to be built before OpenStack is installed.
OpenCrowbar was designed to deploy platforms like Ceph. It has detailed knowledge of the physical infrastructure and sufficient orchestration to synchronize Ceph Mon cluster bring-up.
We are only at the start of the Ceph install journey. Today, you can use the open source components to bring up a Ceph cluster in a reliable way that works across hardware vendors. Much remains to optimize and tune this configuration to take advantage of SSDs, non-Centos environments and more.
We’d love to work with you to tune and extend this workload! Please join us in the OpenCrowbar community.
 After writing pages of notes about the impact of Docker, microservice architectures, mainstreaming of Ops Automation, software defined networking, exponential data growth and the explosion of alternative hardware architecture, I realized that it all boils down to the death of cloud as we know it.
After writing pages of notes about the impact of Docker, microservice architectures, mainstreaming of Ops Automation, software defined networking, exponential data growth and the explosion of alternative hardware architecture, I realized that it all boils down to the death of cloud as we know it.
OK, we’re not killing cloud per se this year. It’s more that we’ve put 10 pounds of cloud into a 5 pound bag so it’s just not working in 2015 to call it cloud.
Cloud was happily misunderstood back in 2012 as virtualized infrastructure wrapped in an API beside some platform services (like object storage).
That illusion will be shattered in 2015 as we fully digest the extent of the beautiful and complex mess that we’ve created in the search for better scale economics and faster delivery pipelines. 2015 is going to cause a lot of indigestion for CIOs, analysts and wandering technology executives. No one can pick the winners with Decisive Leadership™ alone because there are simply too many possible right ways to solve problems.
Here’s my list of the seven cloud disrupting technologies and frameworks that will gain even greater momentum in 2015:
Today these seven items create complexity and confusion as we work to balance the new concepts and technologies. I can see a path forward that redefines IT to be both more flexible and dynamic while also being stable and performing.
Want more 2015 predictions? Here’s my OpenStack EOY post about limiting/expanding the project scope.
Sometimes a solving a small problem well makes a huge impact for operators. Talking to operators, it appears that automated configuration of Squid does exactly that.

If you were installing OpenStack or Hadoop, you would not find “setup a squid proxy fabric to optimize your package downloads” in the install guide. That’s simply out of scope for those guides; however, it’s essential operational guidance. That’s what I mean by open operations and creating a platform for sharing best practice.
Deploying a base operating system (e.g.: Centos) on a lot of nodes creates bit-tons of identical internet traffic. By default, each node will attempt to reach internet mirrors for packages. If you multiply that by even 10 nodes, that’s a lot of traffic and a significant performance impact if you’re connection is limited.
For OpenCrowbar developers, the external package resolution means that each dev/test cycle with a node boot (which is up to 10+ times a day) is bottle necked. For qa and install, the problem is even worse!
Our solution was 1) to embed Squid proxies into the configured environments and the 2) automatically configure nodes to use the proxies. By making this behavior default, we improve the overall performance of a deployment. This further improves the overall network topology of the operating environment while adding improved control of traffic.
This is a great example of how Crowbar uses existing operational tool chains (Chef configures Squid) in best practice ways to solve operations problems. The magic is not in the tool or the configuration, it’s that we’ve included it in our out-of-the-box default orchestrations.
It’s time to stop fumbling around in the operational dark. We need to compose our tool chains in an automated way! This is how we advance operational best practice for ready state infrastructure.
 I’m excited to be announcing OpenCrowbar’s first release, Anvil, for the community. Looking back on our original design from June 2012, we’ve accomplished all of our original objectives and more.
I’m excited to be announcing OpenCrowbar’s first release, Anvil, for the community. Looking back on our original design from June 2012, we’ve accomplished all of our original objectives and more.
I was invited to be part of Mark Stouse’s 2014 big data & cloud predictions series. His questions had me thinking deeply about the past year and I’m happy to repost them here with links to the other predictors too including (Robert Scoble, Shel Israel, and David H. Deans).
1. Describe in one sentence what you do and why you’re good at it.
I specialize in architecture for infrastructure software for scale data center operations (aka “cloud”) and I have 14 years of battle scars that inform my designs.
2. Cloud Computing, Big Data or Consumerization: Which trend do you feel is having the most impact on IT today and why?
Cloud, Data & Consumerization are all connected, so there’s no one clear “most impactful” winner except that all three are forcing IT to rethink how we handle operations. The pace of change for these categories (many of which are open source driven) is so fast that traditional IT governance cannot keep up. I’m specifically talking about the DevOps and Lean Software Delivery paradigms. These approaches do not mean that we’re trading speed for quality; in fact, I’ve seen that we’re adopting techniques that deliver both higher quality and speed.
3. What do you think is the biggest misconception about Cloud computing/Big Data/Consumerization?
That someone can purchase them as a SKU. These are really architectural concepts that impact how we solve problems instead of specific products. My experience is that customers overlook their need to understand how to change their business to take advantage of these technologies. It’s the same classic challenge for ROI from most new technologies – they don’t exist apart from the business matching changes to the business to leverage them.
4. Which (Cloud Computing/Big Data/Consumerization) trend has surprised you most in the last five years?
Open source has surprised me because we’ve seen it transform from a cost concern into a supply chain concern. When I started doing open source work for Dell, customers were very interested in innovation and controlling license costs. This has really changed over the last few years. Today, customers are more concerned with community participation and transparency of their product code base. This surprised me until I realized that they are really seeking to ensure that they had maximum control and visibility into their “IT Supply Chain.” It may seem like a paradox, but open source software is uniquely positioned to help companies maintain more control of their critical IT because they are not tightly coupled to a single vendor.
5. How has Cloud Computing/Big Data/Consumerization had the biggest impact in YOUR life to date?
Beyond it being my career, I believe these technologies have created a new degree of freedom for me. I’m answering these questions from the SFO airport where I’m carrying all of the tools I need to do my job in a space small enough to fit under the seat in front of me plus a free Wifi connection. I believe we are only just learning how access to information and portable computing will change our experience. This learning process will be both liberating and painful as we work out the right balances between access, identity and privacy.
6. On a lighter note – If Cloud/Big Data/Consumerization could be personified by a superhero, which superhero would it be and why?
The Hulk. Looks like a friendly geek but it’s going to crush you if you’re not careful.
7. What aspect of (Cloud Computing/Big Data/ Consumerization) are you most excited about in the future, and what excites you about it?
The Internet of Things (even if I hate the term) is very exciting because we’re moving into a place where we have real ways to connect our virtual and physical lives. That translates into cool technologies like self-driving cars and smart power utilities. I think it will also motivate a revolution in how people interact with computers and each other. It’s going to open up a whole new dimension on our personal interaction with our surroundings. I’m specifically thinking about a book “Rainbows End” by Vernor Vinge that paints this future in vivid detail.
 Today, Dell (my employer) announced a plethora of updates to our open source derived solutions (OpenStack and Hadoop). These solutions include the latest bits (Grizzly and Cloudera) for each project. And there’s another important notice for people tracking the Crowbar project: we’ve opened the remainder of its provisioning capability.
Today, Dell (my employer) announced a plethora of updates to our open source derived solutions (OpenStack and Hadoop). These solutions include the latest bits (Grizzly and Cloudera) for each project. And there’s another important notice for people tracking the Crowbar project: we’ve opened the remainder of its provisioning capability.
Yes, you can now build the open version of Crowbar and it has the code to configure a bare metal server.
Let me be very specific about this… my team at Dell tests Crowbar on a limited set of hardware configurations. Specifically, Dell server versions R720 + R720XD (using WSMAN and iIDRAC) and C6220 + C8000 (using open tools). Even on those servers, we have a limited RAID and NIC matrix; consequently, we are not positioned to duplicate other field configurations in our lab. So, while we’re excited to work with the community, caveat emptor open source.
Another thing about RAID and BIOS is that it’s REALLY HARD to get right. I know this because our team spends a lot of time testing and tweaking these, now open, parts of Crowbar. I’ve learned that doing hard things creates value; however, it’s also means that contributors to these barclamps need to be prepared to get some silicon under their fingernails.
I’m proud that we’ve reached this critical milestone and I hope that it encourages you to play along.
PS: It’s worth noting is that community activity on Crowbar has really increased. I’m excited to see all the excitement.
 Scale out platforms like Hadoop have different operating rules. I heard an interesting story today in which the performance of the overall system was improved 300% (run went from 15 mins down to 5 mins) by the removal of a node.
Scale out platforms like Hadoop have different operating rules. I heard an interesting story today in which the performance of the overall system was improved 300% (run went from 15 mins down to 5 mins) by the removal of a node.
In a distributed system that coordinates work between multiple nodes, it only takes one bad node to dramatically impact the overall performance of the entire system.
Finding and correcting this type of failure can be difficult. While natural variability, hardware faults or bugs cause some issues, the human element is by far the most likely cause. If you can turn down noise injected by human error then you’ve got a chance to find the real system related issues.
Consequently, I’ve found that management tooling and automation are essential for success. Management tools help diagnose the cause of the issue and automation creates repeatable configurations that reduce the risk of human injected variability.
I’d also like to give a shout out to benchmarks as part of your tooling suite. Without having a reasonable benchmark it would be impossible to actually know that your changes improved performance.
Teaming Related Post Script: In considering the concept of system performance, I realized that distributed human systems (aka teams) have a very similar characteristic. A single person can have a disproportionate impact on overall team performance.

Whew….Yesterday, Dell announced TWO OpenStack block storage capabilities (Equallogic & Ceph) for our OpenStack Essex Solution (I’m on the Dell OpenStack/Crowbar team) and community edition. The addition of block storage effectively fills the “persistent storage” gap in the solution. I’m quadrupally excited because we now have:
Frankly, I’ve been having trouble sitting on the news until Dell World because both features have been available in Github before the announcement (EQLX and Ceph-Barclamp). Such is the emerging intersection of corporate marketing and open source.
As you may expect, we are delivering them through Crowbar; however, we’ve already had customers pickup the EQLX code and apply it without Crowbar.

If you are using Crowbar 1.5 (Essex 2) then you already have the code! Of course, you still need to have the admin information for your SAN – we did not automate the configuration of the storage system, but the Nova Volume integration.
We have it under a split test so you need to do the following to enable the configuration options:
Want Docs? Got them! Check out these > EQLX Driver Install Addendum
Usage note: the integration uses SSH sessions. It has been performance tested but not been tested at scale.
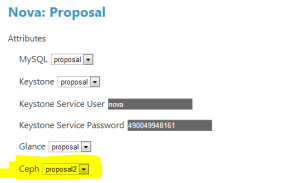
The Ceph capability includes a Ceph barclamp! That means that all the work to setup and configure Ceph is done automatically done by Crowbar. Even better, their Nova barclamp (Ceph provides it from their site) will automatically find the Ceph proposal and link the components together!
Ceph has provided excellent directions and videos to support this install.
 Today my boss at Dell, John Igoe, is part of announcing of the report from the TechAmerica Federal Big Data Commission (direct pdf), I was fully expecting the report to be a real snoozer brimming with corporate synergies and win-win externalities. Instead, I found myself reading a practical guide to applying Big Data to government. Flipping past the short obligatory “what is…” section, the report drives right into a survey of practical applications for big data spanning nearly every governmental service. Over half of the report is dedicated to case studies with specific recommendations and buying criteria.
Today my boss at Dell, John Igoe, is part of announcing of the report from the TechAmerica Federal Big Data Commission (direct pdf), I was fully expecting the report to be a real snoozer brimming with corporate synergies and win-win externalities. Instead, I found myself reading a practical guide to applying Big Data to government. Flipping past the short obligatory “what is…” section, the report drives right into a survey of practical applications for big data spanning nearly every governmental service. Over half of the report is dedicated to case studies with specific recommendations and buying criteria.
Ultimately, the report calls for agencies to treat data as an asset. An asset that can improve how government operates.
There are a few items that stand out in this report:
I strongly agree with one repeated point in the report: although there is more data available, our ability to comprehend this data is reduced. The sheer volume of examples the report cites is proof enough that agencies are, and will be continue to be, inundated with data.
One short coming of this report is that it does not flag the extreme storage of data scientists. Many of the cases discussed assume a ready army of engineers to implement these solutions; however, I’m uncertain how the government will fill positions in a very tight labor market. Ultimately, I think we will have to simply open the data for citizen & non-governmental analysis because, as the report clearly states, data is growing faster than capability to use it.
I commend the TechAmerica commission for their Big Data clarity: success comes from starting with a narrow scope. So the answer, ironically, is in knowing which questions we want to ask.
