
Whew….Yesterday, Dell announced TWO OpenStack block storage capabilities (Equallogic & Ceph) for our OpenStack Essex Solution (I’m on the Dell OpenStack/Crowbar team) and community edition. The addition of block storage effectively fills the “persistent storage” gap in the solution. I’m quadrupally excited because we now have:
- both open source (Ceph) and enterprise (Equallogic) choices
- both Nova drivers’ code is in the open at part of our open source Crowbar work
Frankly, I’ve been having trouble sitting on the news until Dell World because both features have been available in Github before the announcement (EQLX and Ceph-Barclamp). Such is the emerging intersection of corporate marketing and open source.
As you may expect, we are delivering them through Crowbar; however, we’ve already had customers pickup the EQLX code and apply it without Crowbar.
The Equallogic+Nova Connector

If you are using Crowbar 1.5 (Essex 2) then you already have the code! Of course, you still need to have the admin information for your SAN – we did not automate the configuration of the storage system, but the Nova Volume integration.
We have it under a split test so you need to do the following to enable the configuration options:
- Install OpenStack as normal
- Create the Nova proposal
- Enter “Raw” Attribute Mode
- Change the “volume_type” to “eqlx”
- Save
- The Equallogic options should be available in the custom attribute editor! (of course, you can edit in raw mode too)
Want Docs? Got them! Check out these > EQLX Driver Install Addendum
Usage note: the integration uses SSH sessions. It has been performance tested but not been tested at scale.
The Ceph+Nova Connector
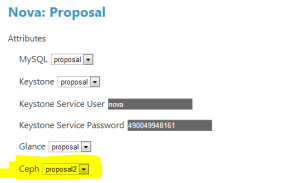
The Ceph capability includes a Ceph barclamp! That means that all the work to setup and configure Ceph is done automatically done by Crowbar. Even better, their Nova barclamp (Ceph provides it from their site) will automatically find the Ceph proposal and link the components together!
Ceph has provided excellent directions and videos to support this install.
 We had an informal
We had an informal 



 However, I wanted to take a minute to update the community about Swift and Nova recipes that we are intenionally leaking out to the community in advance of the larger Crowbar code drop.
However, I wanted to take a minute to update the community about Swift and Nova recipes that we are intenionally leaking out to the community in advance of the larger Crowbar code drop.
