The following material will be a major part of the discussion for The OpenStack Board meeting on Monday 10/20. Comments and suggest welcome!
 Author’s 2/26/2015 Note: This proposal was approved by the Board in October 2014.
Author’s 2/26/2015 Note: This proposal was approved by the Board in October 2014.
For nearly two years, the OpenStack Board has been moving towards creating a common platform definition that can help drive interoperability. At the last meeting, the Board paused to further review one of the core tenants of the DefCore process (Item #3: Core definition can be applied equally to all usage models).
Outside of my role as DefCore chair, I see the OpenStack community asking itself an existential question: “are we one platform or a suite of projects?” I’m having trouble believing “we are both” is an acceptable answer.
During the post-meeting review, Mark Collier drafted a Foundation supported recommendation that basically creates an additional core tier without changing the fundamental capabilities & designated code concepts. This proposal has been reviewed by the DefCore committee (but not formally approved in a meeting).
The original DefCore proposed capabilities set becomes the “platform” level while capability subsets are called “components.” We are considering two initial components, Compute & Object, and both are included in the platform (see illustration below). The approach leaves the door open for new core component to exist both under and outside of the platform umbrella.
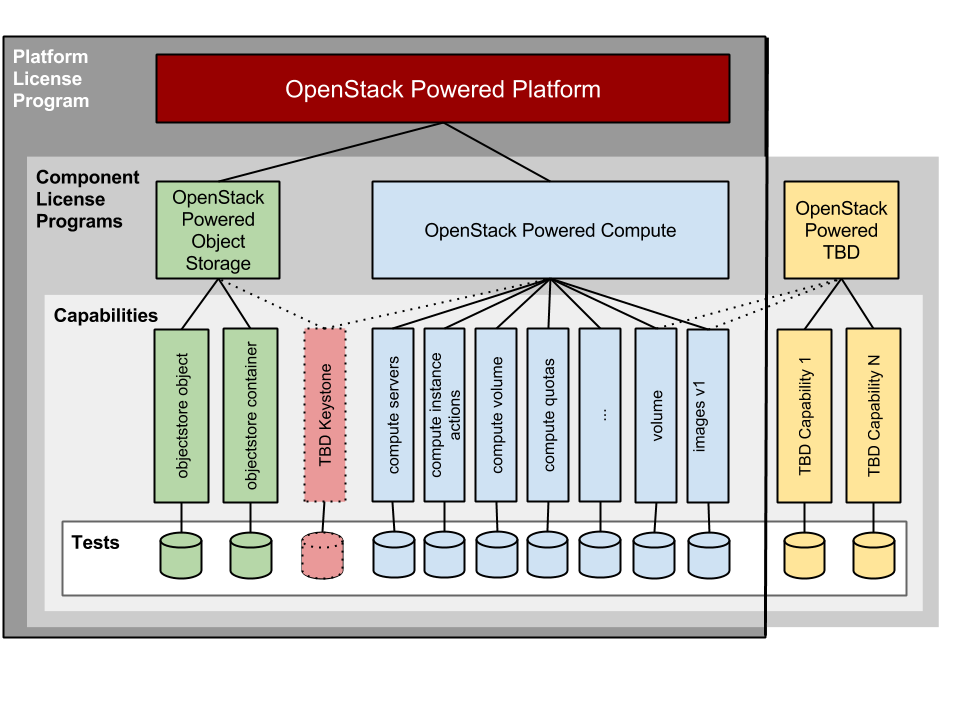
In the proposal, OpenStack vendors who meet either component or platform requirements can qualify for the “OpenStack Powered” logo; however, vendors using the only a component (instead of the full platform) will have more restrictive marks and limitations about how they can use the term OpenStack.
This approach addresses the “is Swift required?” question. For platform, Swift capabilities will be required; however, vendors will be able to implement the Compute component without Swift and implement the Object component without Nova/Glance/Cinder.
It’s important to note that there is only one yard stick for components or the platform: the capabilities groups and designed code defined by the DefCore process. From that perspective, OpenStack is one consistent thing. This change allows vendors to choose sub-components if that serves their business objectives.
It’s up to the community to prove the platform value of all those sub-components working together.

 However, I wanted to take a minute to update the community about Swift and Nova recipes that we are intenionally leaking out to the community in advance of the larger Crowbar code drop.
However, I wanted to take a minute to update the community about Swift and Nova recipes that we are intenionally leaking out to the community in advance of the larger Crowbar code drop.

