A few weeks ago, I posted about VMs being squeezed between containers and metal. That observation comes from our experience fielding the latest metal provisioning feature sets for OpenCrowbar; consequently, so it’s exciting to see the team has cut the next quarterly release: OpenCrowbar v2.2 (aka Camshaft). Even better, you can top it off with official software support.

Dual overhead camshaft housing by Neodarkshadow from Wikimedia Commons
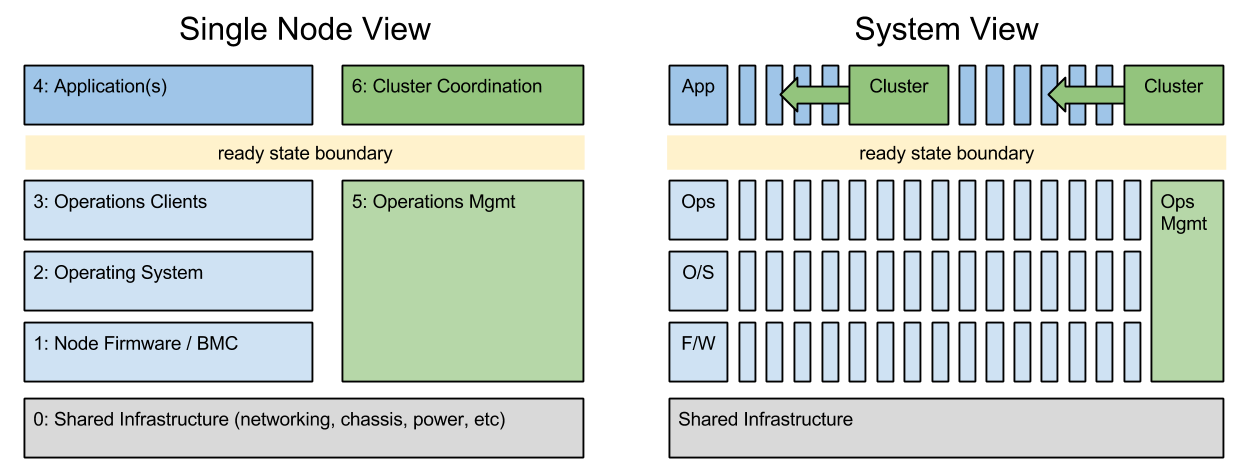
The Camshaft release had two primary objectives: Integrations and Services. Both build on the unique functional operations and ready state approach in Crowbar v2.
1) For Integrations, we’ve been busy leveraging our ready state API to make physical servers work like a cloud. It gets especially interesting with the RackN burn-in/tear-down workflows added in. Our prototype Chef Provisioning driver showed how you can use the Crowbar API to spin servers up and down. We’re now expanding this cloud-like capability for Saltstack, Docker Machine and Pivotal BOSH.
2) For Services, we’ve taken ops decomposition to a new level. The “secret sauce” for Crowbar is our ability to interweave ops activity between components in the system. For example, building a cluster requires setting up pieces on different systems in a very specific sequence. In Camshaft, we’ve added externally registered services (using Consul) into the orchestration. That means that Crowbar will either use existing DNS, Database, or NTP services or set it’s own. Basically, Crowbar can now work FIT YOUR EXISTING OPS ENVIRONMENT without forcing a dedicated Crowbar only services like DHCP or DNS.
In addition to all these features, you can now purchase support for OpenCrowbar from RackN (my company). The Enterprise version includes additional server life-cycle workflow elements and features like HA and Upgrade as they are available.
There are AMAZING features coming in the next release (“Drill”) including a message bus to broadcast events from the system, more operating systems (ESXi, Xenserver, Debian and Mirantis’ Fuel) and increased integration/flexibility with existing operational environments. Several of these have already been added to the develop branch.
It’s easy to setup and test OpenCrowbar using containers, VMs or metal. Want to learn more? Join our community in Gitter, email list or weekly interactive community meetings (Wednesdays @ 9am PT).
 Like any scale install, once you’ve got a solid foundation, the actual installation goes pretty quickly. In Kubernetes’ case, that means creating strong networking and etcd configuration.
Like any scale install, once you’ve got a solid foundation, the actual installation goes pretty quickly. In Kubernetes’ case, that means creating strong networking and etcd configuration. Want more background on StackEngine?
Want more background on StackEngine? 

 Today, we’re ready to help people run and expand OpenCrowbar (days away from v2.1!). We’re also seeking investment to make the project more “enterprise-ready” and build integrations that extend ready state.
Today, we’re ready to help people run and expand OpenCrowbar (days away from v2.1!). We’re also seeking investment to make the project more “enterprise-ready” and build integrations that extend ready state.