RackN creates infrastructure agnostic automation so you can run physical and cloud infrastructure with the same elastic operational patterns. If you want to make infrastructure unimportant then your hybrid DevOps objective is simple:
Create multi-infrastructure Amazon equivalence for ops automation.
 Even if you are not an AWS fan, they are the universal yardstick (15 minute & 40 minute presos) That goes for other clouds (public and private) and for physical infrastructure too. Their footprint is simply so pervasive that you cannot ignore “works on AWS” as a need even if you don’t need to work on AWS. Like PCs in the late-80s, we can use vendor competition to create user choice of infrastructure. That requires a baseline for equivalence between the choices. In the 90s, the Windows’ monopoly provided those APIs.
Even if you are not an AWS fan, they are the universal yardstick (15 minute & 40 minute presos) That goes for other clouds (public and private) and for physical infrastructure too. Their footprint is simply so pervasive that you cannot ignore “works on AWS” as a need even if you don’t need to work on AWS. Like PCs in the late-80s, we can use vendor competition to create user choice of infrastructure. That requires a baseline for equivalence between the choices. In the 90s, the Windows’ monopoly provided those APIs.
Why should you care about hybrid DevOps? As we increase operational portability, we empower users to make economic choices that foster innovation. That’s valuable even for AWS locked users.
We’re not talking about “give me a VM” here! The real operational need is to build accessible, interconnected systems – what is sometimes called “the underlay.” It’s more about networking, configuration and credentials than simple compute resources. We need consistent ways to automate systems that can talk to each other and static services, have access to dependency repositories (code, mirrors and container hubs) and can establish trust with other systems and administrators.
These “post” provisioning tasks are sophisticated and complex. They cannot be statically predetermined. They must be handled dynamically based on the actual resource being allocated. Without automation, this process becomes manual, glacial and impossible to maintain. Does that sound like traditional IT?
Side Note on Containers: For many developers, we are adding platforms like Docker, Kubernetes and CloudFoundry, that do these integrations automatically for their part of the application stack. This is a tremendous benefit for their use-cases. Sadly, hiding the problem from one set of users does not eliminate it! The teams implementing and maintaining those platforms still have to deal with underlay complexity.
I am emphatically not looking for AWS API compatibility: we are talking about emulating their service implementation choices. We have plenty of ways to abstract APIs. Ops is a post-API issue.
In fact, I believe that red herring leads us to a bad place where innovation is locked behind legacy APIs. Steal APIs where it makes sense, but don’t blindly require them because it’s the layer under them where the real compatibility challenge lurk.
Side Note on OpenStack APIs (why they diverge): Trying to implement AWS APIs without duplicating all their behaviors is more frustrating than a fresh API without the implied AWS contracts. This is exactly the problem with OpenStack variation. The APIs work but there is not a behavior contract behind them.
For example, transitioning to IPv6 is difficult to deliver because Amazon still relies on IPv4. That lack makes it impossible to create hybrid automation that leverages IPv6 because they won’t work on AWS. In my world, we had to disable default use of IPv6 in Digital Rebar when we added AWS. Another example? Amazon’s regional AMI pattern, thankfully, is not replicated by Google; however, their lack means there’s no consistent image naming pattern. In my experience, a bad pattern is generally better than inconsistent implementations.
As market dominance drives us to benchmark on Amazon, we are stuck with the good, bad and ugly aspects of their service.
For very pragmatic reasons, even AWS automation is highly fragmented. There are a large and shifting number of distinct system identifiers (AMIs, regions, flavors) plus a range of user-configured choices (security groups, keys, networks). Even within a single provider, these options make impossible to maintain a generic automation process. Since other providers logically model from AWS, we will continue to expect AWS like behaviors from them. Variation from those norms adds effort.
Failure to follow AWS without clear reason and alternative path is frustrating to users.
Do you agree? Join us with Digital Rebar creating real a hybrid operations platform.

 Despite his fortune and fame, there was a period in the middle of Prince’s career in which he felt creatively and financially locked-in by the big record companies. Once Prince (and the unpronounceable symbol) broke away from Warner Music, he was able to produce music under his own label. This action enabled him to create music without a major record label dictating when he needed to produce a new album and what it needed to sound like. In addition, he was now able to market his new recordings to the distribution platform that supported his artistic and financial goals. While still having ties to Warner Music, he was no longer bound by their business practices. Along with starting his own music subscription service, Prince cut deals with Arista, Columbia, iTunes and Sony. Prince’s music production had operational portability, business agility and choice (seven Grammy awards and 100 million record sales also help create that kind of leverage.).
Despite his fortune and fame, there was a period in the middle of Prince’s career in which he felt creatively and financially locked-in by the big record companies. Once Prince (and the unpronounceable symbol) broke away from Warner Music, he was able to produce music under his own label. This action enabled him to create music without a major record label dictating when he needed to produce a new album and what it needed to sound like. In addition, he was now able to market his new recordings to the distribution platform that supported his artistic and financial goals. While still having ties to Warner Music, he was no longer bound by their business practices. Along with starting his own music subscription service, Prince cut deals with Arista, Columbia, iTunes and Sony. Prince’s music production had operational portability, business agility and choice (seven Grammy awards and 100 million record sales also help create that kind of leverage.). We think Kubernetes is an awesome way to run applications at scale! Unfortunately, there’s a bootstrapping problem: we need good ways to build secure & reliable scale environments around Kubernetes. While some parts of the platform administration leverage the platform (cool!), there are fundamental operational topics that need to be addressed and questions (like upgrade and conformance) that need to be answered.
We think Kubernetes is an awesome way to run applications at scale! Unfortunately, there’s a bootstrapping problem: we need good ways to build secure & reliable scale environments around Kubernetes. While some parts of the platform administration leverage the platform (cool!), there are fundamental operational topics that need to be addressed and questions (like upgrade and conformance) that need to be answered. Here’s the summary:
Here’s the summary: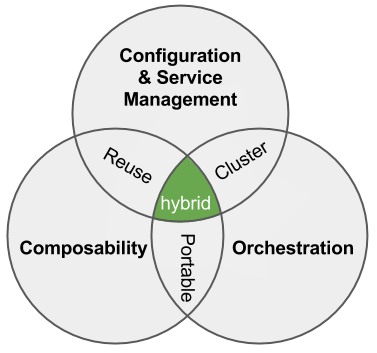 Here’s our write-up:
Here’s our write-up:  I’ve struggled with the term “underlay” for infrastructure of a long time. At
I’ve struggled with the term “underlay” for infrastructure of a long time. At 