During the OpenStack summit, Eric Wright (@discoposse) and I talked about a wide range of topics from scoring success of OpenStack early goals to burning down traditional data centers.
Why burn down your data center (and move to public cloud)? Because your ops process are too hard to change. Rob talks about how hybrid provides a path if we can made ops more composable.
Here are my notes from the audio podcast (source):
1:30 Why “zehicle” as a handle? Portmanteau from electrics cars… zero + vehicle
Let’s talk about OpenStack & Cloud…
- OpenStack History
- 2:15 Rob’s OpenStack history from Dell and Hyperscale
- 3:20 Early thoughts of a Cloud API that could be reused
- 3:40 The practical danger of Vendor lock-in
- 4:30 How we implemented “no main corporate owner” by choice
- About the Open in OpenStack
- 5:20 Rob decomposes what “open” means because there are multiple meanings
- 6:10 Price of having all open tools for “always open” choice and process
- 7:10 Observation that OpenStack values having open over delivering product
- 8:15 Community is great but a trade off. We prioritize it over implementation.
- Q: 9:10 What if we started later? Would Docker make an impact?
- Part of challenge for OpenStack was teaching vendors & corporate consumers “how to open source”
- Q: 10:40 Did we accomplish what we wanted from the first summit?
- Mixed results – some things we exceeded (like growing community) while some are behind (product adoption & interoperability).
- 13:30 Interop, Refstack and Defcore Challenges. Rob is disappointed on interop based on implementations.
- Q: 15:00 Who completes with OpenStack?
- There are real alternatives. APIs do not matter as much as we thought.
- 15:50 OpenStack vendor support is powerful
- Q: 16:20 What makes OpenStack successful?
- Big tent confuses the ecosystem & push the goal posts out
- “Big community” is not a good definition of success for the project.
- 18:10 Reality TV of open source – people like watching train wrecks
- 18:45 Hybrid is the reality for IT users
- 20:10 We have a need to define core and focus on composability. Rob has been focused on the link between hybrid and composability.
- 22:10 Rob’s preference is that OpenStack would be smaller. Big tent is really ecosystem projects and we want that ecosystem to be multi-cloud.
Now, about RackN, bare metal, Crowbar and Digital Rebar….
- 23:30 (re)Intro
- 24:30 VC market is not metal friendly even though everything runs on metal!
- 25:00 Lack of consistency translates into lack of shared ops
- 25:30 Crowbar was an MVP – the key is to understand what we learned from it
- 26:00 Digital Rebar started with composability and focus on operations
- 27:00 What is hybrid now? Not just private to public.
- 30:00 How do we make infrastructure not matter? Multi-dimensional hybrid.
- 31:00 Digital Rebar is orchestration for composable infrastructure.
- Q: 31:40 Do people get it?
- Yes. Automation is moving to hybrid devops – “ops is ops” and it should not matter if it’s cloud or metal.
- 32:15 “I don’t want to burn down my data center” – can you bring cloud ops to my private data center?
 We dove into a discussion around significant trends in the container space, how open technology relates to containers and looked toward the technology’s future. We also previewed next month’s
We dove into a discussion around significant trends in the container space, how open technology relates to containers and looked toward the technology’s future. We also previewed next month’s 
 Despite his fortune and fame, there was a period in the middle of Prince’s career in which he felt creatively and financially locked-in by the big record companies. Once Prince (and the unpronounceable symbol) broke away from Warner Music, he was able to produce music under his own label. This action enabled him to create music without a major record label dictating when he needed to produce a new album and what it needed to sound like. In addition, he was now able to market his new recordings to the distribution platform that supported his artistic and financial goals. While still having ties to Warner Music, he was no longer bound by their business practices. Along with starting his own music subscription service, Prince cut deals with Arista, Columbia, iTunes and Sony. Prince’s music production had operational portability, business agility and choice (seven Grammy awards and 100 million record sales also help create that kind of leverage.).
Despite his fortune and fame, there was a period in the middle of Prince’s career in which he felt creatively and financially locked-in by the big record companies. Once Prince (and the unpronounceable symbol) broke away from Warner Music, he was able to produce music under his own label. This action enabled him to create music without a major record label dictating when he needed to produce a new album and what it needed to sound like. In addition, he was now able to market his new recordings to the distribution platform that supported his artistic and financial goals. While still having ties to Warner Music, he was no longer bound by their business practices. Along with starting his own music subscription service, Prince cut deals with Arista, Columbia, iTunes and Sony. Prince’s music production had operational portability, business agility and choice (seven Grammy awards and 100 million record sales also help create that kind of leverage.). We think Kubernetes is an awesome way to run applications at scale! Unfortunately, there’s a bootstrapping problem: we need good ways to build secure & reliable scale environments around Kubernetes. While some parts of the platform administration leverage the platform (cool!), there are fundamental operational topics that need to be addressed and questions (like upgrade and conformance) that need to be answered.
We think Kubernetes is an awesome way to run applications at scale! Unfortunately, there’s a bootstrapping problem: we need good ways to build secure & reliable scale environments around Kubernetes. While some parts of the platform administration leverage the platform (cool!), there are fundamental operational topics that need to be addressed and questions (like upgrade and conformance) that need to be answered. Even if you are not an AWS fan,
Even if you are not an AWS fan,  Here’s the summary:
Here’s the summary: If you get an F4-E1 (washer pump bad) code, then you MUST clear the code after you replace the drive motor. The reset code is pressing any three bottons in a 1-2-3 sequence three times (so 1-2-3, 1-2-3, 1-2-3). I took a picture of my unit with all lights on after I entered the diagnostic code.
If you get an F4-E1 (washer pump bad) code, then you MUST clear the code after you replace the drive motor. The reset code is pressing any three bottons in a 1-2-3 sequence three times (so 1-2-3, 1-2-3, 1-2-3). I took a picture of my unit with all lights on after I entered the diagnostic code.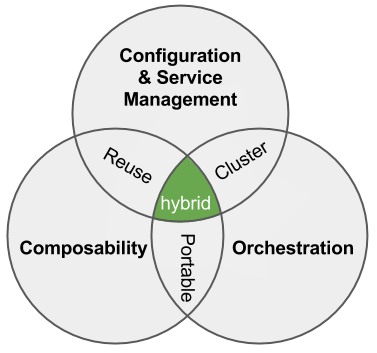 Here’s our write-up:
Here’s our write-up: 