Like my previous DefCore interop windmill tilting, this is not something that can be done alone. Open infrastructure is a collaborative effort and I’m looking for your help and support. I believe solving this problem benefits us as an industry and individually as IT professionals.
 So, what is open infrastructure? It’s not about running on open source software. It’s about creating platform choice and control. In my experience, that’s what defines open for users (and developers are not users).
So, what is open infrastructure? It’s not about running on open source software. It’s about creating platform choice and control. In my experience, that’s what defines open for users (and developers are not users).
I’ve spent several years helping lead OpenStack interoperability (aka DefCore) efforts to ensure that OpenStack cloud APIs are consistent between vendors. I strongly believe that effort is essential to build an ecosystem around the project; however, in talking to enterprise users, I’ve learned that that their real interoperability gap is between that many platforms, AWS, Google, VMware, OpenStack and Metal, that they use everyday.
Instead of focusing inward to one platform, I believe the bigger enterprise need is to address automation across platforms. It is something I’m starting to call hybrid DevOps because it allows users to mix platforms, service APIs and tools.
Open infrastructure in that context is being able to work across platforms without being tied into one platform choice even when that platform is based on open source software. API duplication is not sufficient: the operational characteristics of each platform are different enough that we need a different abstraction approach.
We have to be able to compose automation in a way that tolerates substitution based on infrastructure characteristics. This is required for metal because of variation between hardware vendors and data center networking and services. It is equally essential for cloud because of variation between IaaS capabilities and service delivery models. Basically, those minor differences between clouds create significant challenges in interoperability at the operational level.
Rationalizing APIs does little to address these more structural differences.
The problem is compounded because the differences are not nicely segmented behind abstraction layers. If you work to build and sustain a fully integrated application, you must account for site specific needs throughout your application stack including networking, storage, access and security. I’ve described this as all deployments have 80% of the work common but the remaining 20% is mixed in with the 80% instead of being nicely layers. So, ops is cookie dough not vinaigrette.
Getting past this problem for initial provisioning on a single platform is a false victory. The real need is portable and upgrade-ready automation that can be reused and shared. Critically, we also need to build upon the existing foundations instead of requiring a blank slate. There is openness value in heterogeneous infrastructure so we need to embrace variation and design accordingly.
This is the vision the RackN team has been working towards with open source Digital Rebar project. We now able to showcase workload deployments (Docker, Kubernetes, Ceph, etc) on multiple cloud platforms that also translate to full bare metal deployments. Unlike previous generations of this tooling (some will remember Crowbar), we’ve been careful to avoid injecting external dependencies into the DevOps scripts.
While we’re able to demonstrate a high degree of portability (or fidelity) across multiple platforms, this is just the beginning. We are looking for users and collaborators who want to want to build open infrastructure from an operational perspective.
You are invited to join us in making open cross-platform operations a reality.
 Here’s the summary:
Here’s the summary: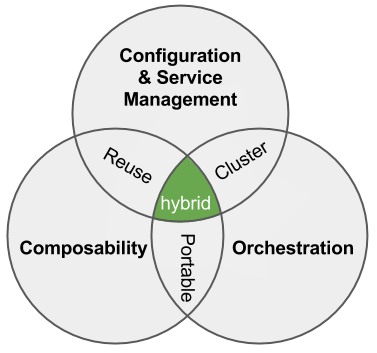 Here’s our write-up:
Here’s our write-up: 

 awareness, you can be more secure WITHOUT putting more work for developers.
awareness, you can be more secure WITHOUT putting more work for developers. I’ve struggled with the term “underlay” for infrastructure of a long time. At
I’ve struggled with the term “underlay” for infrastructure of a long time. At  I believe that application should drive the infrastructure, not the reverse. I’ve heard may times that the “infrastructure should be invisible to the user.” Unfortunately, lack of abstraction and composibility make it difficult to code across platforms. I like the term “
I believe that application should drive the infrastructure, not the reverse. I’ve heard may times that the “infrastructure should be invisible to the user.” Unfortunately, lack of abstraction and composibility make it difficult to code across platforms. I like the term “