Apparently this is “Showcase Dell OpenStack/Crowbar Team Member Week” because today I’m proxy positioning for Dell OpenStack engineer Chris Dearborn. Chris has been leading our OpenStack Neutron deployment for Grizzly and Havana.
Apparently this is “Showcase Dell OpenStack/Crowbar Team Member Week” because today I’m proxy positioning for Dell OpenStack engineer Chris Dearborn. Chris has been leading our OpenStack Neutron deployment for Grizzly and Havana.
If you’re familiar with the OpenStack Networking, skip over my introductory preamble and jump right down to the meat under “SDN Client Connection: Linux Bridge.” Hopefully we can convince Chris to put together more in this series and cover GRE and VLAN configurations too.
OpenStack and Software Defined Network
Software Defined Networking (SDN) is an emerging concept that describes a family of functionality. Like cloud, the exact meaning of SDN appears to be in the eye (or brochure) of the company providing the technology. Overall, the concept for SDN is to have programmable networks that can be automatically provisioned.
Early approaches to this used the OpenFlow™ API to programmatically modify switch routing tables (aka OSI Layer 2) on a flow by flow basis across multiple switches. While highly controlled, OpenFlow has proven difficult to implement at scale in dynamic environments; consequently, many SDN implementations are now using overlay networks based on inventoried VLANs and/or dynamic tunnels.
Inventoried VLAN overlay networks create a stable base layer 2 infrastructure that can be inventoried and handed out dynamically on-demand. Generally, the management infrastructure dynamically connects the end-points (typically virtual machines) to a dedicated existing layer 2 network. This provides all of the isolation desired without having to thrash the underlying network switch infrastructure.
Dynamic tunnel overlay network also uses client connection points to isolate traffic but do not rely on switch layer 2. Instead, they encrypt traffic before sending it over a shared network. This avoids having to match dynamic networks to static inventory; however, it also adds substantial encryption overhead to the network communication. Consequently, tunnels provide more flexibility and less up front-confirmation but with lower performance.
OpenStack Networking, project Neutron (previously Quantum), is responsible for connecting virtual machines setup by OpenStack Compute (aka Nova) to the software defined networking infrastructure. By design, Neutron accommodates different implementation plug-ins. That allows operators to choose between different approaches including the addition of commercial offerings. While it is possible to use open source capabilities for small deployments and trials, most large scale deployments choose proprietary SDN technologies.
The Crowbar OpenStack installation allows operators to choose between “Open vSwitch GRE Tunnels” and “Linux Bridge VLAN” configuration. The GRE option is more flexible and requires less up front configuration; however, the encryption used by GRE will degrade performance. The Linux Bridge VLAN option requires more upfront configuration and design.
Since GRE works with minimal configuration, let’s explore what’s required to for Crowbar to setup OpenStack Neutron Linux Bridge VLAN networking.
Note: This review assumes that you already have a working knowledge of Crowbar and OpenStack.
Background
Before we dig into how OpenStack configures SDN , we need to understand how we connect between virtual machines running in the system and the physical network. This connection uses Linux Bridges. For GRE tunnels, Crowbar configures an Open vSwitch (aka OVS) on the node to create and manage the tunnels.
One challenge with SDN traffic isolation is that we can no longer assume that virtual machines with network access can reach destinations on our same network. This means that the infrastructure must provide paths (aka gateways and routers) between the tenant and infrastructure networks. A major part of the OpenStack configuration includes setting up these connections when new tenant networks are created.
Note: In the OpenStack Grizzly and earlier releases, open source code for network routers were not configured in a highly available or redundant way. This problem is addressed in the Havana release.
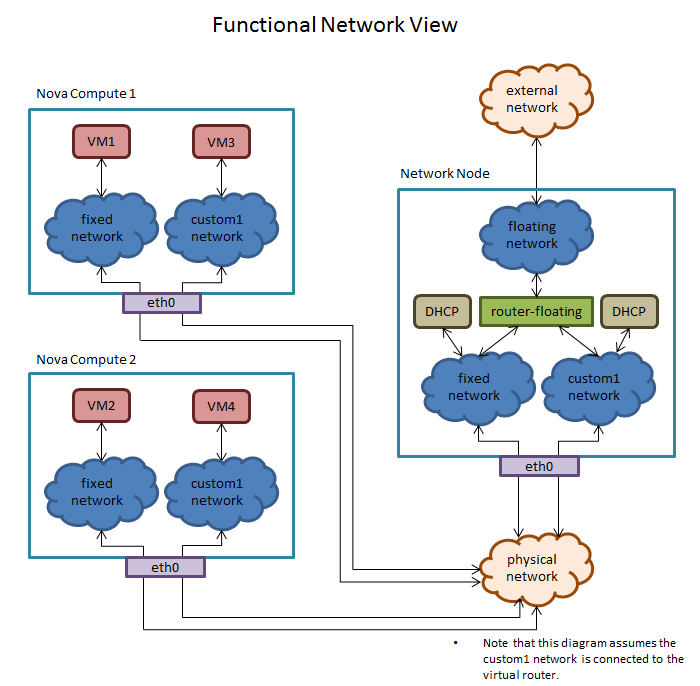
For the purposes of this explanation, the “network node” is the shared infrastructure server that bridges networks. The “compute node” is any one of the servers hosting guest virtual machines. Traffic in the cloud can be between virtual machines within the cloud instance (internal) or between a virtual machine and something outside the OpenStack cloud instance (external).
Let’s make sure we’re on the same page with terminology.
- OSI Layer 2 – just above physical connections (layer 1), Layer two manages traffic between servers including providing logical separation of traffic.
- VLAN – Virtual Local Area Network are switch enforced isolation zones created by adding 1 of 4096 tags in the network traffic (aka tagged traffic).
- Tenant – a group of users in a cloud that are logically isolated (cannot see other traffic or information) but still using shared resources.
- Switch – a physical device used to provide layer 1 networking connections between end points. May provide additional services on other OSI layers such as VLANs.
- Network Node – an OpenStack infrastructure server that connects tenant networks to infrastructure networks.
- Compute Node – an OpenStack server that runs user workloads in virtual machines or containers.
SDN Client Connection: Linux Bridge

The VLAN range for Linux Bridge is configurable in /etc/quantum/quantum.conf by changing the network_vlan_ranges parameter. Note that this parameter is set by the Crowbar Neutron chef recipe. The VLAN range is configured to start at whatever the “vlan” attribute in the nova_fixed network in the bc-template-network.json is set to. The VLAN range end is hard coded to end at the VLAN start plus 2000.
Reminder: The maximum VLAN tag is 4096 so the VLAN tag for nova_fixed should never be set to anything greater than 2095 to be safe.
Networks are assigned the next available VLAN tag as they are created. For instance, the first manually created network will be assigned VLAN 501, the next VLAN 502, etc. Note that this is independent of what tenant the new network resides in.
The convention in Linux Bridge is to name the various network constructs including the first 11 characters of the UUID of the associated Neutron object. This allows you to run the quantum CLI command listing out the objects you are interested in, and grepping on the 11 uuid characters from the network construct name. This shows what Neutron object a given network construct maps to.

Network Creation
When a network is created, a corresponding bridge is created and is given the name br<network_uuid>. A subinterface of the NIC is also created and is named <interface_name>.<vlan_tag>. This subinterface is slaved to the bridge. Note that this only happens when the network is needed (when a VM is created on the network).
This occurs on both the network node and the compute nodes.
Additional Steps Taken On The Network Node During Network Creation
On the network node, a bridge and subinterface is created per network and the subinterface is slaved to the bridge as described above. If the network is attached to the router, then a TAP interface that the router listens on is created and slaved to the bridge. If DHCP is selected, then another TAP interface is created that the dnsmasq process talks to, and that interface is also slaved to the bridge.
VM Creation On A Compute Node
When a VM is created, a TAP interface is created and named tap<port_uuid>. The port is the Neutron port that the VM is plugged in to. This TAP interface is slaved to the bridge associated with the network that the user selected when creating the VM. Note that this occurs on compute nodes only.
Determining the dnsmasq port/tap interface for a network
The TAP port associated with dnsmasq for a network can be determined by first getting the uuid of the network, then looking on the network node in /var/lib/quantum/dhcp/<network_uuid>/interface. The interface will be named ns-. Note that this is only the first 11 characters of the uuid. The tap interface will be named tap.

Summary
Understanding OpenStack Networking is critical to operating a successful cloud deployment. The Crowbar Team at Dell has invested significant effort to automate the configuration of Neutron. This helps you eliminate the risk of manual configuration and leverage our extensive testing and field experience.
If you are interested in seeing the exact sequences used by Crowbar, please visit the Crowbar Github repository for the “Quantum Barclamp.”
 Overall, I’m happy with our three days of hacking on Crowbar 2. We’ve reached the critical “deploys workload” milestone and I’m excited about well the design is working and how clearly we’ve been able to articulate our approach in code & UI.
Overall, I’m happy with our three days of hacking on Crowbar 2. We’ve reached the critical “deploys workload” milestone and I’m excited about well the design is working and how clearly we’ve been able to articulate our approach in code & UI.