I’ve been digging into what it means to be a site reliability engineer (SRE) and thinking about my experience trying to automate infrastructure in a way to scales dramatically better. I’m not thinking about scale in number of nodes, but in operator efficiency. The primary way to create that efficiency is limit site customization and to improve reuse. Those changes need to start before the first install.
As an industry, we must address the “day 2” problem in collaboratively developed open software before users’ first install.
Recently, RackN asked the question “Shouldn’t we have Shared Automation for Commodity Infrastructure?” which talked about fact that we, as an industry, keep writing custom automation for what should be commodity servers. This “snow flaking” happens because there’s enough variation at the data center system level that it’s very difficult to share and reuse automation on an ongoing basis.
Since variation enables innovation, we need to solve this problem without limiting diversity of choice.

Happily, platforms like Kubernetes are designed to hide these infrastructure variations for developers. That means we can expect a productivity explosion for the huge number of applications that can narrowly target platforms. Unfortunately, that does nothing for the platforms or infrastructure bound applications. For this lower level software, we need to accept that operations environments are heterogeneous.
I realized that we’re looking at a multidimensional problem after watching communities like OpenStack struggle to evolve operations practice.
It’s multidimensional because we are building the operations practice simultaneously with the software itself. To make things even harder, the infrastructure and dependencies are also constantly changing. Since this degree of rapid multi-factor innovation is the new normal, we have to plan that our operations automation itself must be as upgradable.
If we upgrade both the software AND the related deployment automation then each deployment will become a cul-de-sac after day 1.
For open communities, that cul-de-sac challenge limits projects’ ability to feed operational improvements back into the user base and makes it harder for early users to stay current. These challenges limit the virtuous feedback cycles that help communities grow.
The solution is to approach shared project deployment automation as also being continuously deployed.
This is a deceptively hard problem.
This is a hard problem because each deployment is unique and those differences make it hard to absorb community advances without being constantly broken. That is one of the reasons why company opt out of the community and into vendor distributions. While Vendors are critical to the ecosystem, the practice ultimately limits the growth and health of the community.
Our approach at RackN, as reflected in open Digital Rebar, is to create management abstractions that isolate deployment variables based on system level concerns. Unlike project generated templates, this approach absorbs heterogeneity and brings in the external information that often complicate project deployment automation.
We believe that this is a general way to solve the broader problem and invite you to participate in helping us solve the Day 2 problems that limit our open communities.
 Why should you sponsor? Current OpenStack operators facing “fork-lift upgrades” should want to find a path like this one that ensures future upgrades are baked into the plan. This approach provide a fast track to a general purpose, enterprise grade, upgradable Kubernetes infrastructure.
Why should you sponsor? Current OpenStack operators facing “fork-lift upgrades” should want to find a path like this one that ensures future upgrades are baked into the plan. This approach provide a fast track to a general purpose, enterprise grade, upgradable Kubernetes infrastructure. The Kubernetes Helm work out of the
The Kubernetes Helm work out of the 


 Digital Rebar
Digital Rebar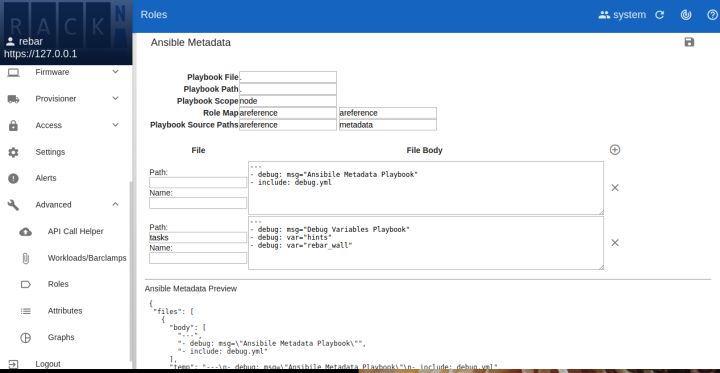
 With our latest patches (short demo videos below), you can now create single role Ansible or Bash scripts dynamically and then incorporate them into the node execution.
With our latest patches (short demo videos below), you can now create single role Ansible or Bash scripts dynamically and then incorporate them into the node execution. This is a significant advance in provisioning infrastructure because it allows bootstrapping
This is a significant advance in provisioning infrastructure because it allows bootstrapping 
