Today, I’m sharing a parable about always being focused on adding value.
Recently, I was on a call with an IT Ops manager who insisted that his team had their on-premises operations under control with “python scripts and manual kickstart files” because they “really don’t change their infrastructure setup.” He explained that he and his team was comfortable with this because it was something they understood and did not require learning new systems. While I understand his position, I was sort of sad for him and his employer because…
No value is created for his company by maintaining custom kickstart, preseeds or boot files.
Maintaining kickstarts is fatal for many reasons. Is there a way to make it less fatal? Yes, and it involves investing in learning tools that let you move up stack.
Contrary to popular IT mythology, managing physical infrastructure is still a reality for many IT teams and will remain a part of best practices until every workload simply runs on Amazon and it becomes their problem. Since that “Utopian” future is unlikely, let’s deal with some practical realities of hybrid IT.
Here are my six reasons why custom kickstarts (and other site-specific boot provisioning scripts) are dangerous:
1. Creating Site Unique Processes
Every infrastructure is unique and that’s a practical reality that we have to accept because otherwise we would never be able to make improvements and corrects without touching everything that already deployed. However, we really want to work hard to minimize places where we inject variation into the environment. That means that server and site specific kickstarts with lots of post-provisioning steps forces operators to maintain additional information about each server.
2. Building Server Specific Configurations
When we create server specific templates, it becomes nearly impossible to recreate server builds. That directly leads to fragile infrastructure because teams cannot quickly redeploy or automate refreshes. Static IT infrastructure is a known fail pattern and makes enterprises vulnerable to staff changes, hacking and inability to manage and patch.
3. Having Opaque Configurations
Kickstart is hard to understand (and even harder to troubleshoot). When teams take actions during the provisioning process they are often not tracked or managed like other operational scripting tools. Failures or injections can easily go undetected. Even if they are tracked, the number of operators who can read and manage these scripts is limited. That means that critical aspects of your operational environment happen outside of your awareness.
4. Being Less Secure
Kickstart processes generally include injecting SSH keys, certificates and other authentication credentials. These embedded credentials are often hard coded into the process with minimal awareness of the operational team leaving you vulnerable at the most foundational level. This is not an acceptable security process; however, teams who hack kickstarts often don’t want to consider the implications.
Security side note: most teams don’t have the expertise to integrate TPM or HSM into their kickstart processes; consequently, these key security technologies are generally unused and ignored. If you want to talk about this, please contact me!
5. Diverging Provisioning Patterns
Cloud does not use kickstarts. Provisioning variation increases when teams keep/add logic and configuration into server provisioning instead of doing it as post-provision automation. If your physical provisioning team is not rehearsing on cloud then you’re in a serious IT hole because all workloads should be managed as hybrid-ready. Deployment fidelity helps accelerate teams and reduces cost.
6. Reusing Community Practice
Finally, managing your own kickstarts makes it impossible to leverage community patterns and practices. Kickstarts are not exactly a hive of innovation so you are not creating any competitive advantage by adding variation there. In cases like that, reusing community tooling is a net benefit to your organization. Why have we not done this already? Until recently, provisioning tools were not API driven or focused on reusable shared practice.
While Kickstart or similar is pretty much required for physical, we have a solution for these issues.
One of the key design elements of Digital Rebar is an templated, API driven boot provisioner. Our approach uses kickstarts, preseeds and other tools; however, we’ve worked hard to minimize their span and decompose them into reusable components. That allows users to inject site specific code as snippets that are centrally managed and hardware neutral.
Critically, our approach allows SRE and Ops teams to get out of the kickstart business and focus on provisioning workflow and automation. Yes, there’s some learning curve but there are a lot of benefits to moving up stack.
It’s not too late to “:q!” those kickstart edits and accelerate your infrastructure.
 The Kubernetes Helm work out of the AT&T Comm Dev lab takes on the integration with a “do it the K8s native way” approach that the RackN team finds very effective. In fact, we’ve created a fully integrated Digital Rebar deployment that lays down Kubernetes using Kargo and then adds OpenStack via Helm. The provisioning automation includes a Ceph cluster to provide stateful sets for data persistence.
The Kubernetes Helm work out of the AT&T Comm Dev lab takes on the integration with a “do it the K8s native way” approach that the RackN team finds very effective. In fact, we’ve created a fully integrated Digital Rebar deployment that lays down Kubernetes using Kargo and then adds OpenStack via Helm. The provisioning automation includes a Ceph cluster to provide stateful sets for data persistence.  Given the rise of SRE thinking, the RackN team believes that this approach changes the field for OpenStack deployments and will ultimately dominate the field (which is already mainly containerized). There is still work to be completed: some complex configuration is required to allow both Kubernetes CNI and Neutron to collaborate so that containers and VMs can cross-communicate.
Given the rise of SRE thinking, the RackN team believes that this approach changes the field for OpenStack deployments and will ultimately dominate the field (which is already mainly containerized). There is still work to be completed: some complex configuration is required to allow both Kubernetes CNI and Neutron to collaborate so that containers and VMs can cross-communicate. My focus on
My focus on 


 Digital Rebar
Digital Rebar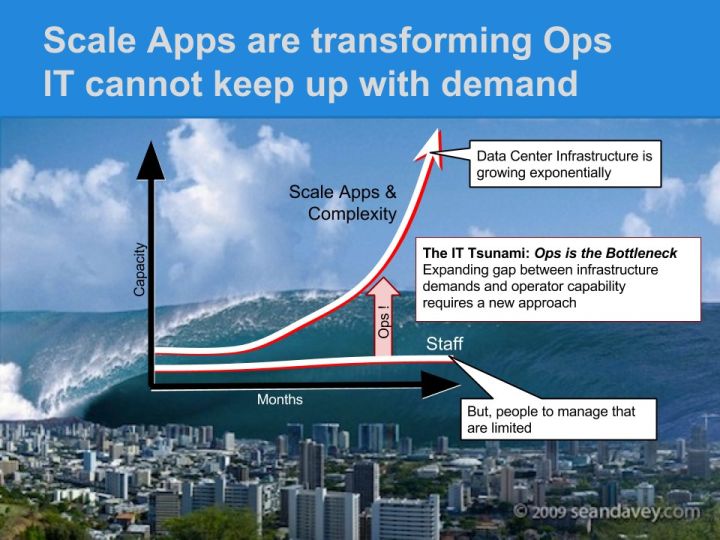

 Meanwhile, we’re in the midst of an Enterprise revolt against running infrastructure. Companies, for very good reasons, are shutting down internal IT efforts in favor of using outsourced infrastructure. Operations has simply not been able to complete with the capability, flexibility and breadth of infrastructure services offered by Amazon.
Meanwhile, we’re in the midst of an Enterprise revolt against running infrastructure. Companies, for very good reasons, are shutting down internal IT efforts in favor of using outsourced infrastructure. Operations has simply not been able to complete with the capability, flexibility and breadth of infrastructure services offered by Amazon.