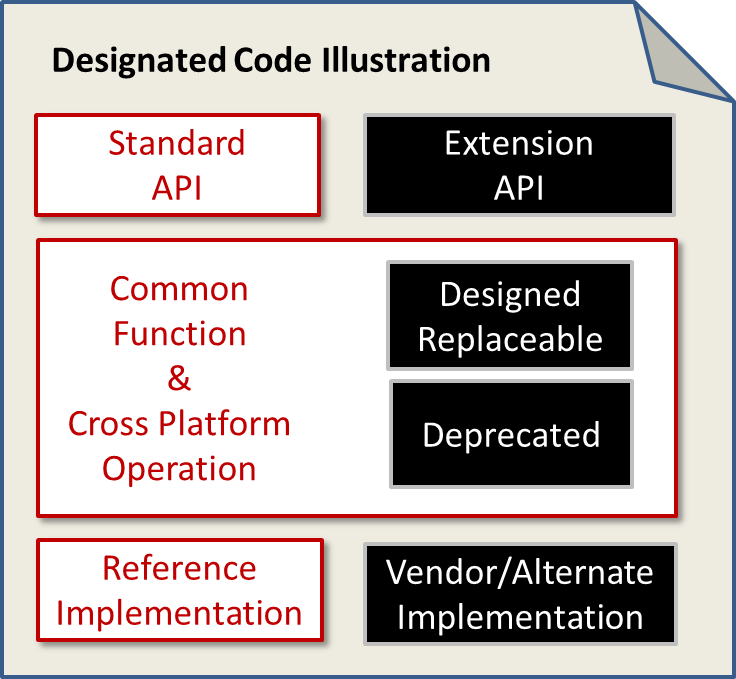
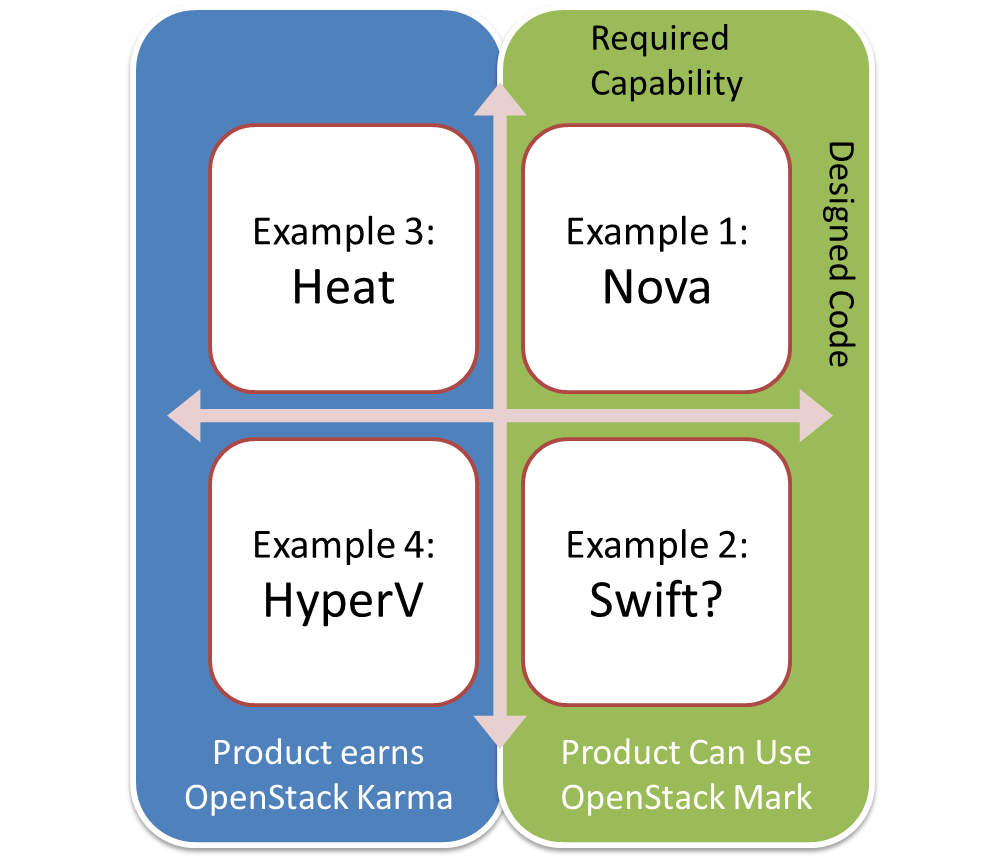
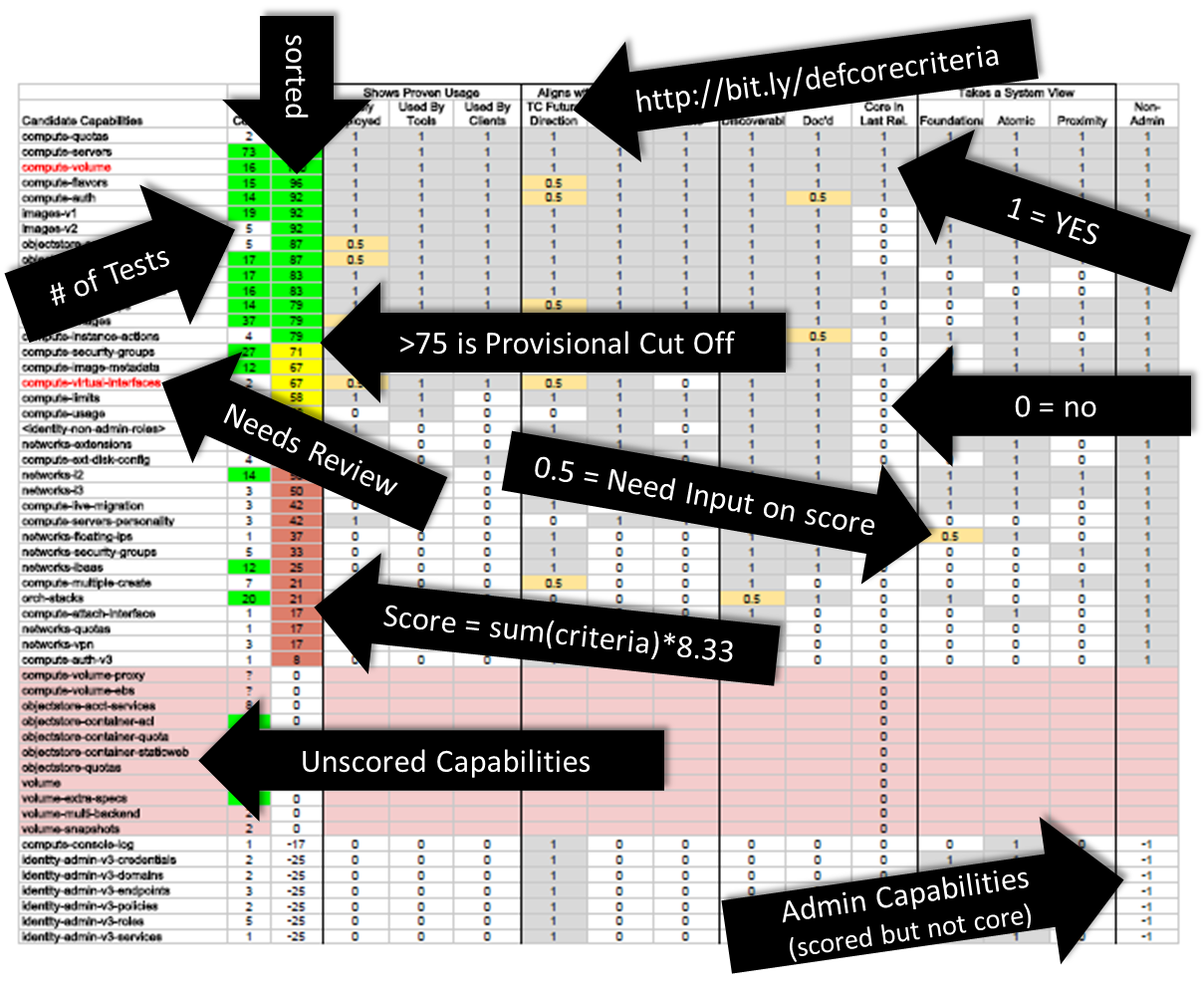
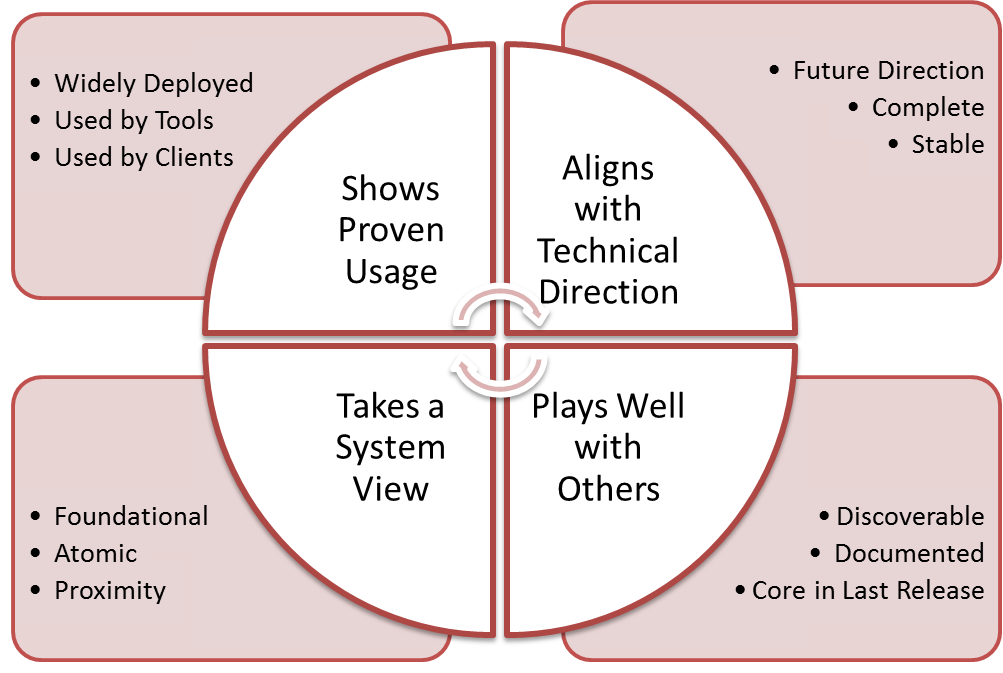
After the summit (#afterstack), a few of us compared notes and found a common theme in an under served but critical part of the OpenStack community. Sean Roberts (HIS POST), Allison Randal (her post), and I committed to expand our discussion to the broader community.
 Lack of Product Management¹ was a common theme at the Atlanta OpenStack summit. That effectively adds fuel to the smoldering “lacking a benevolent dictator” commentary that lingers like smog at summits. While I’ve come think this criticism has merit, I think that it’s a dramatic oversimplification of the leadership dynamic. We have plenty of leaders in OpenStack but we don’t do enough to coordinate them because they are hidden.
Lack of Product Management¹ was a common theme at the Atlanta OpenStack summit. That effectively adds fuel to the smoldering “lacking a benevolent dictator” commentary that lingers like smog at summits. While I’ve come think this criticism has merit, I think that it’s a dramatic oversimplification of the leadership dynamic. We have plenty of leaders in OpenStack but we don’t do enough to coordinate them because they are hidden.
One reason to reject “missing product management” as a description is that there are LOTS of PMs in OpenStack. It’s simply that they all work for competing companies. While we spend a lot of time coordinating developers from competing companies, we have minimal integration between their direct engineering managers or product managers.
We spend a lot of time getting engineering talking together, but we do not formally engage discussion between their product or line managers. In fact, they likely encourage them to send their engineers instead of attending summits themselves; consequently, we may not even know those influencers!
When the managers are omitted then the commitments made by engineers to projects are empty promises.
At best, this results in a discrepancy between expected and actual velocity. At worst, work may be waiting on deliveries that have been silently deprioritized by managers who do not directly participate or simply felt excluded the technical discussion.
We need to recognize that OpenStack work is largely corporate sponsored. These managers directly control the engineers’ priorities so they have a huge influence on what features really get delivered.
To make matters worse (yes, they get worse), these influencers are often invisible. Our tracking systems focus on code committers and completely miss the managers who direct those contributors. Even if they had the needed leverage to set priorities, OpenStack technical and governance leaders may not know who contact to resolve conflicts.
We’ve each been working with these “hidden influencers” at our own companies and they aren’t a shadowy spy-v-spy lot, they’re just human beings. They are every bit as enthusiastic about OpenStack as the developers, users and operators! They are frequently the loudest voices saying “Could you please get us just one or two more headcount for the team, we want X and Y to be able to spend full-time on upstream contribution, but we’re stretched too thin to spare them at the moment”.
So it’s not intent but an omission in the OpenStack project to engage managers as a class of contributors. We have clear avenues for developers to participate, but pretty much entirely ignore the managers. We say that with a note of caution, because we don’t want to bring the managers in to “manage OpenStack”.
We should provide avenues for collaboration so that as they’re managing their team of devs at their company, they are also communicating with the managers of similar teams at other companies.
This is potentially beneficial for developers, managers and their companies: they can gain access to resources across company lines. Instead of being solely responsible for some initiative to work on a feature for OpenStack, they can share initiatives across teams at multiple companies. This does happen now, but the coordination for it is quite limited.
We don’t think OpenStack needs more management; instead, I think we need to connect the hidden influencers. Transparency and dialog will resolve these concerns more directly than adding additional process or controls.