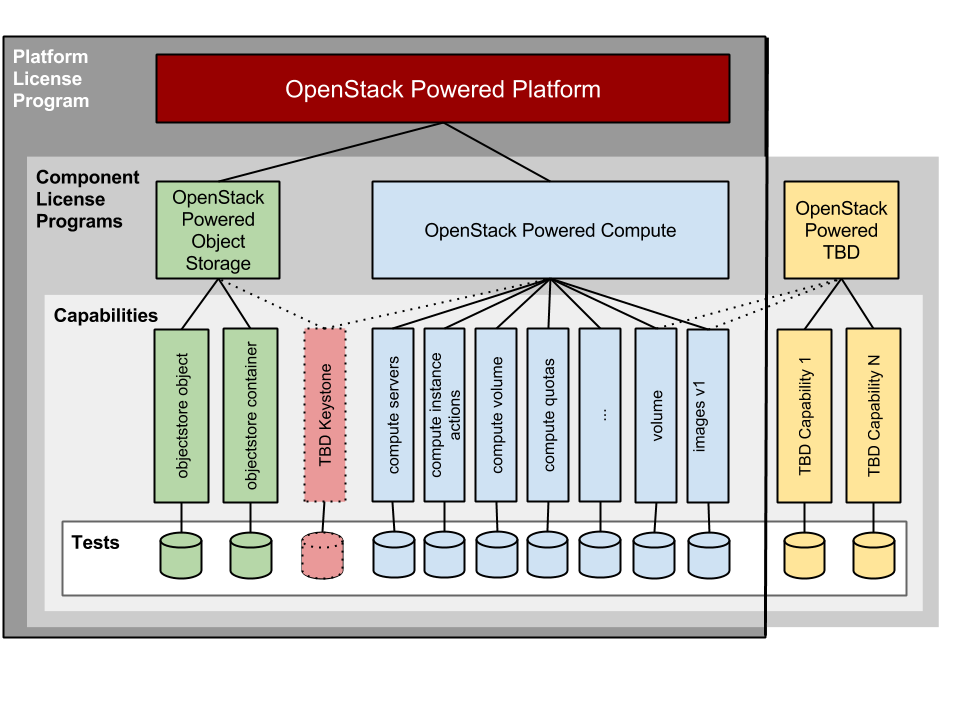
Last week, I was a guest on the NextCast OpenStack podcast hosted by Niki Acosta (EMC) [Jeff Dickey could not join]. I’ve taken some time to transcribe highlights.
We had a great discussion  about OpenStack, Ops and Crowbar. I appreciate Niki’s insightful questions and an opportunity to share my opinions. I feel that we covered years of material in just 1 hour and I appreciate the opportunity to appear on the podcast.
about OpenStack, Ops and Crowbar. I appreciate Niki’s insightful questions and an opportunity to share my opinions. I feel that we covered years of material in just 1 hour and I appreciate the opportunity to appear on the podcast.
Video from full post (youtube) and the audio for download.
Plus, a FULL TRANSCRIPT! Here’s my Next Cast #14 Short Transcripton
The objective of this transcription is to help navigate the recording, not replace it. I did not provide complete context for remarks.
- 04:30 Birth of Crowbar (to address Ops battle scars)
- 08:00 The need for repeatable Ready State baseline to help community work together
- 10:30 Should hardware matter in OpenStack? It has to, details and topology matters not vendor.
- 11:20 OpenCompute – people are trying to open source hardware design
- 11:50 When you are dealing with hardware, it matters. You have to get it right.
- 12:40 Customers are hardware heterogeneous by design (and for ops tooling). Crowbar is neutral territory
- 14:50 It’s not worth telling people they are wrong, because they are not. There are a lot of right ways to install OpenStack
- 16:10 Sometimes people make expensive choices because it’s what they are comfortable with and it’s not helpful for me to them they a wrong – they are not.
- 16:30 You get into a weird corner if you don’t tell anyone no. And an equally weird corner if you tell everyone yes.
- 18:00 Aspirations of having an interoperable cloud was much harder than the actual work to build it
- 18:30 Community want to say yes, “bring your code” but to operators that’s very frustrating because they want to be able to make substitutions
- 19:30 Thinking that if something is included then it’s required – that’s not clear
- 19:50 Interlock Dilemma [see my back reference]
- 20:10 Orwell Animal Farm reference – “all animals equal but pigs are more equal”
- 22:20 Rob defines DefCore, it’s not big and scary
- 22:35 DefCore is about commercial use, not running the technical project
- 23:35 OpenStack had to make money for the companies are paying for the developers who participate… they need to see ROI
- 24:00 OpenStack is an infrastructure project, stability is the #1 feature
- 24:40 You have to give a reason why you are saying no and a path to yes
- 25:00 DefCore is test driven: quantitative results
- 26:15 Balance between whole project and parts – examples are Swiftstack (wants Object only) and Dreamhost (wants Compute only)
- 27:00 DefCore created core components vs platform levels
- 27:30 No vendor has said they can implement DefCore without some effort
- 28:10 We have outlets for vendors who do not want to implement the process
- 28:30 The Board is not in a position to make technical call about what’s in, we had to build a process for community input
- 29:10 We had to define something that could say, “this is it and we have to move on”
- 29:50 What we want is for people to start with the core and then bring in the other projects. We want to know what people are adding so we can make that core in time
- 30:10 This is not a recommendation is a base.
- 30:35 OpenStack is a bubble – does not help if we just get together to pad each other on the back, we want to have a thriving ecosystem
- 31:15 Question: “have vendors been selfish”
- 31:35 Rob rephrased as “does OpenStack have a tragedy of the commons” problem
- 32:30 We need to make sure that everyone is contributing back upstream
- 32:50 Benefit of a Benevolent Dictator is that they can block features unless community needs are met
- 33:10 We have NOT made it clear where companies should be contributing to the community. We are not doing a good job directing community efforts
- 33:45 Hidden Influencers becomes OpenStack Product group
- 34:55 Hidden Influencers were not connecting at the summit in a public way (like developers were)
- 35:20 Developers could not really make big commitments of their time without the buy in from their managers (product and line)
- 35:50 Subtle selfishness – focusing on your own features can disrupt the whole release where things would flow better if they helped others
- 37:40 Rob was concerned that there was a lot of drift between developers and company’s product descriptions
- 38:20 BYLAWS CHANGES – vote! here’s why we need to change
- 38:50 Having whole projects designated as core sucks – code in core should be slower and less changing. Innovation at the core will break interoperability
- 39:40 Hoping that core will help product managers understand where they are using the standard and adding values
- 41:10 All babies are ugly > with core, that’s good. We are looking for the grown ups who can do work and deliver value. Babies are things you nurture and help grow because they have potential.
- 42:00 We undermine our credibility in the community when we talk about projects that are babies as if they were ready.
- 43:15 DefCore’s job was to help pick projects. If everyone is core then we look like a youth soccer team where everyone is getting a trophy
- 44:30 Question: “What do you tell to users to instill confidence in OpenStack”
- 44:50 first thing: focus on operations and automation. Table stakes (for any cloud) is getting your deployments automated. Puppies vs Cattle.
- 45:25 People who were successful with early OpenStack were using automated deployments against the APIs.
- 46:00 DevOps is a fundamental part of cloud computing – if you’re hand-built and not automated then you are old school IT.
- 46:40 Niki references Gartner “Bimodal IT” [excellent reference, go read it!]
- 47:20 VMWare is a great crutch for OpenStack. We can use VMWare for the puppies.
- 47:45 OpenStack is not going to run on every servers (perhaps that’s heresy) but it does not make sense in every workload
- 48:15 One size does not fit all – we need to be good at what we’re good at
- 48:30 OpenStack needs to focus on doing something really well. That means helping people who want to bring automated workloads into the cloud
- 49:20 Core was about sending a signal about what’s ready and people can rely on
- 49:45 Back in 2011, I was saying OpenStack was ready for people who would make the operational investment
- 50:30 We use Crowbar because it makes it easier to do automated deployments for infrastructure like Hadoop and Ceph where you want access to the physical media
- 51:00 We should be encouraging people to use OpenStack for its use cases
- 51:30 Existential question for OpenStack: are we a suite or product. The community is split here
- 51:30 In comparing with Amazon, does OpenStack have to implement it or build an ecosystem to compete
- 53:00 As soon as you make something THE OpenStack project (like Heat) you are sending a message that the alternates are not welcome
- 54:30 OpenStack ends up in a trap if we pick a single project and make it the way that we are going do something. New implementations are going to surface from WITHIN the projects and we need to ready for that.
- 55:15 new implementations are coming, we have to be ready for that. We can make ourselves vulnerable to splitting if we do not prepare.
- 56:00 API vs Implementation? This is something that splits the community. Ultimately we to be an API spec but we are not ready for that. We have a lot of work to do first using the same code base.
- 56:50 DefCore has taken a balanced approach using our diversity as a strength
- 57:20 Bylaws did not allow for enough flexibility for what is core
- 59:00 We need voters for the quorum!
- 59:30 Rob recommended Rocky Grober (Huawei) and Shamail Tahir (EMC) for future shows

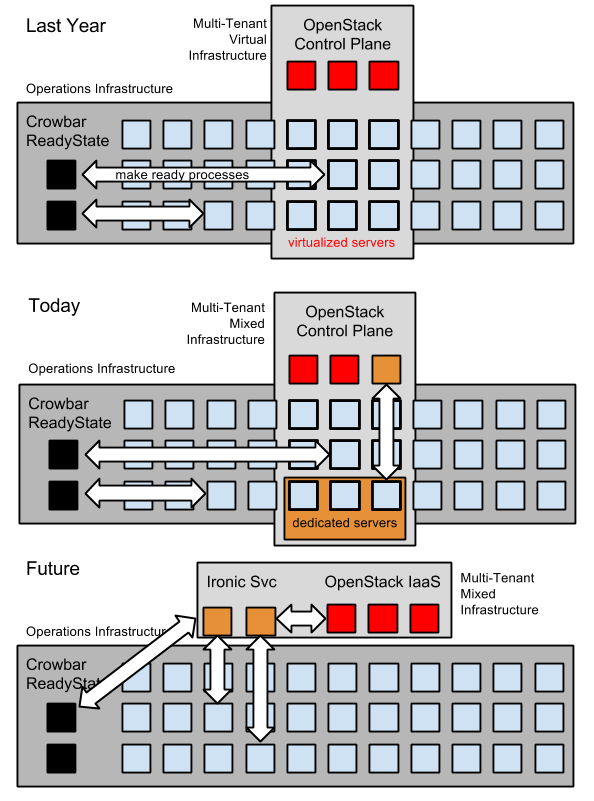




 Author’s 2/26/2015 Note: This proposal was approved by the Board in October 2014.
Author’s 2/26/2015 Note: This proposal was approved by the Board in October 2014.