This post is co-authored by Devanda van der Veen, OpenStack Ironic PTL, and Rob Hirschfeld, OpenCrowbar Founder. We discuss how Ironic and Crowbar work together today and into the future.
Normalizing the APIs for hardware configuration is a noble and long-term goal. While the end result, a configured server, is very easy to describe; the differences between vendors’ hardware configuration tools are substantial. These differences make it impossible challenging to create repeatable operations automation (DevOps) on heterogeneous infrastructure.
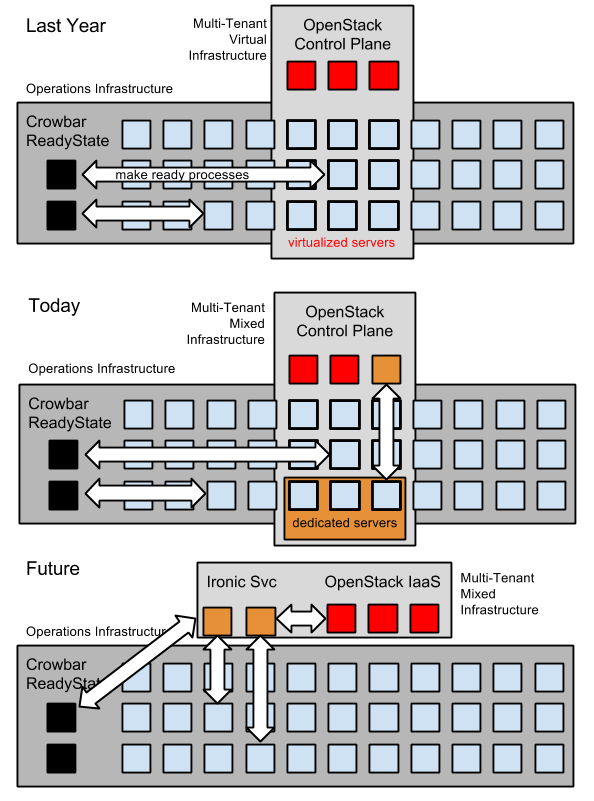
Illustration to show potential changes in provisioning control flow over time.
The OpenStack Ironic project is a multi-vendor community solution to this problem at the server level. By providing a common API for server provisioning, Ironic encourages vendors to write drivers for their individual tooling such as iDRAC for Dell or iLO for HP.
Ironic abstracts configuration and expects to be driven by an orchestration system that makes the decisions of how to configure each server. That type of orchestration is the heart of Crowbar physical ops magic [side node: 5 ways that physical ops is different from cloud]
The OpenCrowbar project created extensible orchestration to solve this problem at the system level. By decomposing system configuration into isolated functional actions, Crowbar can coordinate disparate configuration actions for servers, switches and between systems.
Today, the Provisioner component of Crowbar performs similar functions as Ironic for operating system installation and image lay down. Since configuration activity is tightly coupled with other Crowbar configuration, discovery and networking setup, it is difficult to isolate in the current code base. As Ironic progresses, it should be possible to shift these activities from the Provisioner to Ironic and take advantage of the community-based configuration drivers.
The immediate synergy between Crowbar and Ironic comes from accepting two modes of operation for OpenStack: bootstrapping infrastructure and multi-tenant server allocation.
Crowbar was designed as an operational platform that seeds an OpenStack ready environment. Once that environment is configured, OpenStack can take over ownership of the resources and allow Ironic to manage and deliver “hypervisor-free” servers for each tenant. In that way, we can accelerate the adoption of OpenStack for self-service metal.
Physical operations is messy and challenging, but we’re committed to working together to make it suck less. Operators of the world unite!















