When Dell pulled out from OpenCrowbar last April, I made a commitment to our community to find a way to keep it going. Since my exit from Dell early in October 2014, that commitment has taken the form of RackN.
Today, we’re ready to help people run and expand OpenCrowbar (days away from v2.1!). We’re also seeking investment to make the project more “enterprise-ready” and build integrations that extend ready state.
RackN focuses on maintenance and support of OpenCrowbar for ready state physical provisioning. We will build the community around Crowbar as an open operations core and extend it with a larger set of hardware support and extensions. We are building partnerships to build application integration (using Chef, Puppet, Salt, etc) and platform workloads (like OpenStack, Hadoop, Ceph, CloudFoundry and Mesos) above ready state.
I’ve talked with hundreds of people about the state of physical data center operations at scale. Frankly, it’s a scary state of affairs: complexity is increasing for physical infrastructure and we’re blurring the lines by adding commodity networking with local agents into the mix.
Making this jumble of stuff work together is not sexy cloud work – I describe it as internet plumbing to non-technical friends. It’s unforgiving, complex and full of sharp edge conditions; however, people are excited to hear about our hardware abstraction mission because it solves a real pain for operators.
I hope you’ll stay tuned, or even play along, as we continue the Open Ops journey.










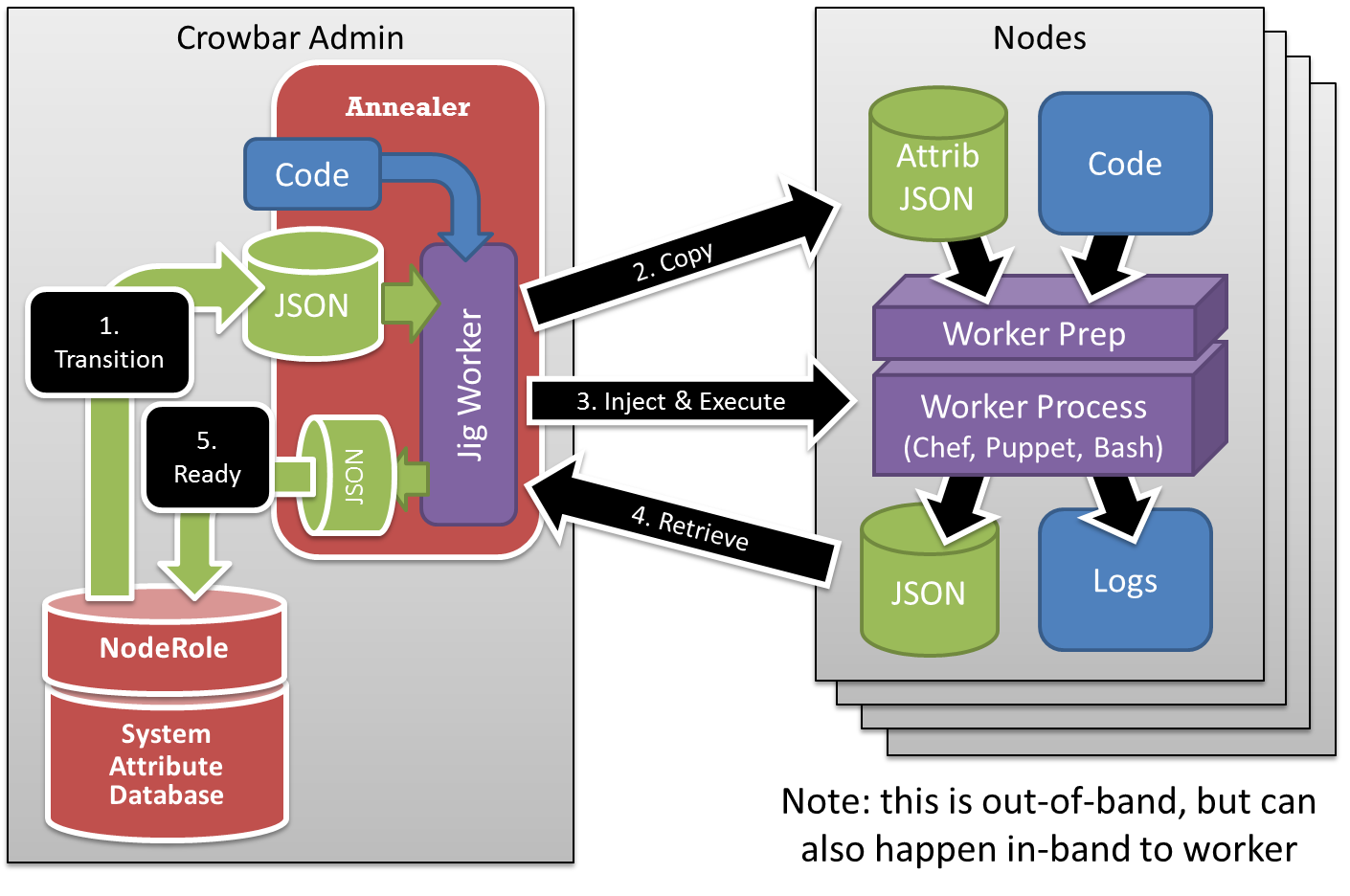
 Emergent services
Emergent services