I’ve posted about the early DefCore core capabilities selection process before and we’ve put them into application and discussed them with the community. The feedback was simple: tl;dr. You’ve got the right direction but make it simpler!
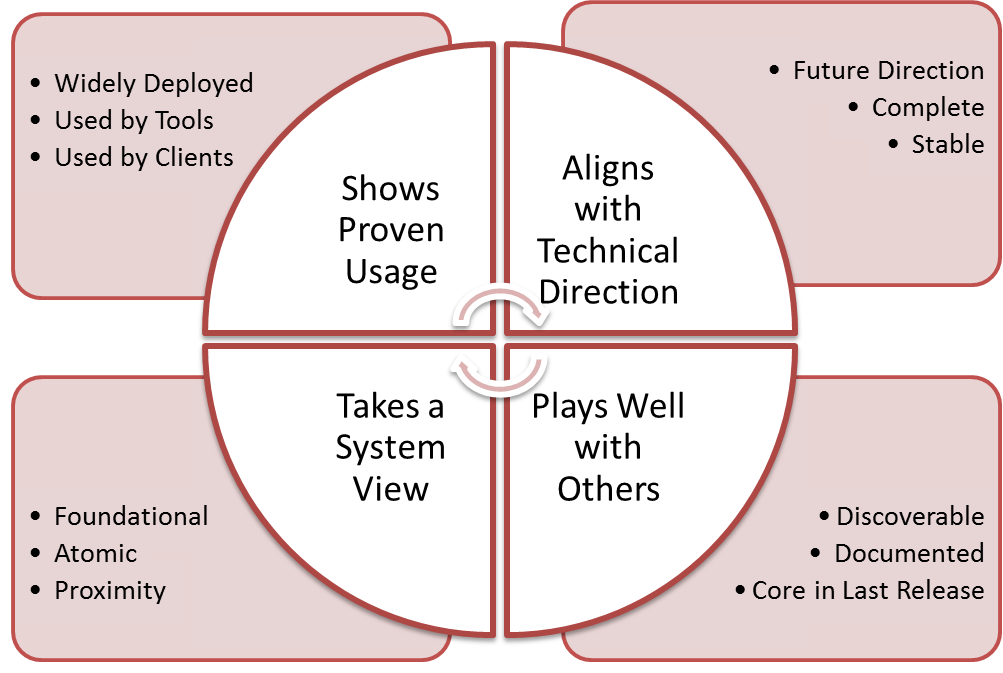
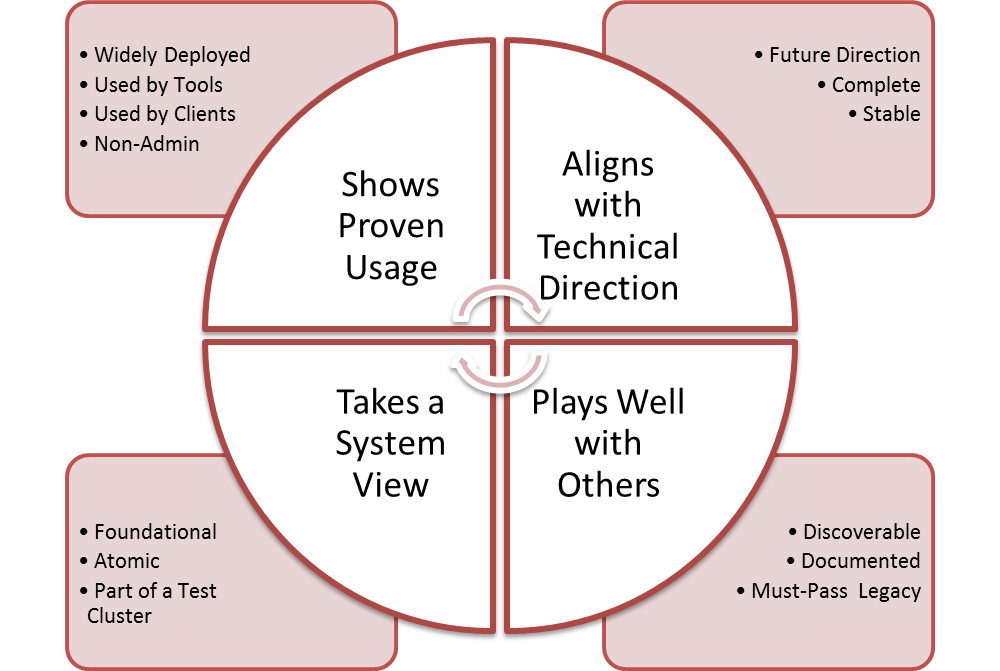
So we pulled the 12 criteria into four primary categories:
- Usage: the capability is widely used (Refstack will collect data)
- Direction: the capability advances OpenStack technically
- Community: the capability builds the OpenStack community experience
- System: the capability integrates with other parts of OpenStack
These categories summarize critical values that we want in OpenStack and so make sense to be the primary factors used when we select core capabilities. While we strive to make the DefCore process objective and quantitive, we must recognize that these choices drive community behavior.
With this perspective, let’s review the selection criteria. To make it easier to cross reference, we’ve given each criteria a shortened name:
Shows Proven Usage
- “Widely Deployed” Candidates are widely deployed capabilities. We favor capabilities that are supported by multiple public cloud providers and private cloud products.
- “Used by Tools” Candidates are widely used capabilities:Should be included if supported by common tools (RightScale, Scalr, CloudForms, …)
- “Used by Clients” Candidates are widely used capabilities: Should be included if part of common libraries (Fog, Apache jclouds, etc)
- “Future Direction” Should reflect future technical direction (from the project technical teams and the TC) and help manage deprecated capabilities.
- “Stable” Test is required stable for >2 releases because we don’t want core capabilities that do not have dependable APIs.
- “Complete” Where the code being tested has a designated area of alternate implementation (extension framework) as per the Core Principles, there should be parity in capability tested across extension implementations. This also implies that the capability test is not configuration specific or locked to non-open technology.
Plays Well with Others
- “Discoverable” Capability being tested is Service Discoverable (can be found in Keystone and via service introspection)
- “Doc’d” Should be well documented, particularly the expected behavior. This can be a very subjective measure and we expect to refine this definition over time.
- “Core in Last Release” A test that is a must-pass test should stay a must-pass test. This make makes core capabilities sticky release per release. Leaving Core is disruptive to the ecosystem
Takes a System View
- “Foundation” Test capabilities that are required by other must-pass tests and/or depended on by many other capabilities
- “Atomic” Capabilities is unique and cannot be build out of other must-pass capabilities
- “Proximity” (sometimes called a Test Cluster) selects for Capabilities that are related to Core Capabilities. This helps ensure that related capabilities are managed together.
Note: The 13th “non-admin” criteria has been removed because Admin APIs cannot be used for interoperability and cannot be considered Core.