 I’m a huge advocate of both behavior and test driven development (BDD & TDD). For the Crowbar 2 refactor, I’ve insisted (with community support) that new code has test coverage to the largest extent possible. While this inflicted some technical debt, it dramatically reduces the risk and effort for new developers to contribute.
I’m a huge advocate of both behavior and test driven development (BDD & TDD). For the Crowbar 2 refactor, I’ve insisted (with community support) that new code has test coverage to the largest extent possible. While this inflicted some technical debt, it dramatically reduces the risk and effort for new developers to contribute.
For open source projects, they are even more important because they allow the community to contribute to the project with confidence.
A core part of this effort has been the Erlang BDD (“bravo delta”) tool that I had started before my team began Crowbar (code link).
I’m a big fan of BDD domain specific languages (DSL) because I think that they are descriptive. Ideally, everyone on the team including marketing and documentation authors should be able to understand and contribute to these tests.
I’ve been training our QA team on how the BDD system works and they are surprised at the clarity of the DSL. By reading the DSL for a feature, then can figure out what the developer had in mind for the system to do. Even better, they can see which use-cases the developer is already testing. Yet the real excitement comes from the potential to collaborate on the feature definitions before the code is written. My blue-sky-with-rainbows hope is that developers and testers will sit down together and review the BDD feature descriptions before code is written (perhaps even during planning). Even short of that nirvana, the BDD feature descriptions provide something that everyone can review and discuss where code (even with verbose documentation) falls short.
Ok, so you already know the benefits of BDD. Why didn’t I do this in the Cucumber? It’s the leading tool and a logical fit for a Rails project like Crowbar. Frankly, I have a love-hate relationship with Cucumber.
- It’s slow. And that does not scale for testing. I’m of the belief that slows tests destroy developer productivity because they encourage distractions. Our BDD is fast and is not yet optimized.
- Too coupled to app framework – you can bypass the UI/API for testing if needed. If I’m doing behavior testing then I want to make sure that everything I test is accessible to the user too.
- While Cucumber has a lot of good “webrat” steps to validate basic web pages, I found that these were very basic and I quickly had to write my own.
- Erlang pattern matching made it much easier to define steps in a logical way with much less RegEx than Cucumber
- Erlang is designed to let us parallelize the tests.
- I like programming in Erlang (and I had started BDD before I started Crowbar)
And it goes beyond just testing our code…
We ultimately want to use the BDD infrastructure to gate Crowbar deployments not just code check-ins. That means that when Crowbar orchestrates an application deployment, the BDD infrastructure will execute tests to verify that the deployment is exhibiting the expected behaviors. If the installation does not pass then Crowbar would roll-back or hold the deployment.
This objective is not new or unique – it’s modus operandi at advanced companies who practice continuous deployment. Our position is that this should be an integral part of the orchestration framework.
One side benefit of the BDD system as designed is that it is also a simulator. We are able to take the same core infrastructure and turn it into a load generator and database populator. Unlike more coupled tools, you can run these from anywhere.
Post Script: Here’s the topic that I’m submitting for presentation at OSCON…
Continue reading →

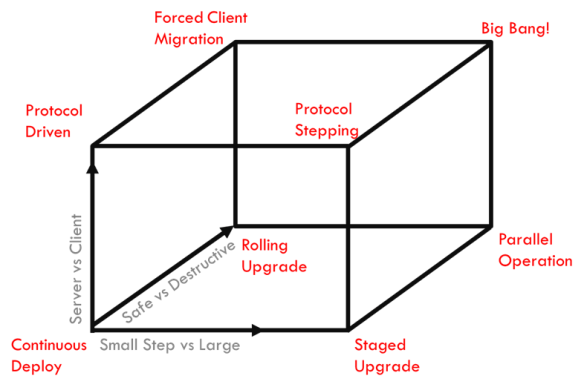







 I’m certain that the
I’m certain that the 