I’ve come to accept that the “Hallway Track” is my primary session at OpenStack events. I want to thank the many people in the community who make that the best track. It’s not only full of deep technical content; there are also healthy doses of intrigue, politics and “let’s fix that” in the halls.
I’ve come to accept that the “Hallway Track” is my primary session at OpenStack events. I want to thank the many people in the community who make that the best track. It’s not only full of deep technical content; there are also healthy doses of intrigue, politics and “let’s fix that” in the halls.
I think honest reflection is critical to OpenStack growth (reflections from last year). My role as a Board member must not translate into pom-pom waving robot cheerleader.
What I heard that’s working:
- Foundation event team did a great job on the logistics and many appreciate the user and operator focus. There’s is no doubt that OpenStack is being deployed at scale and helping transform cloud infrastructure. I think that’s a great message.
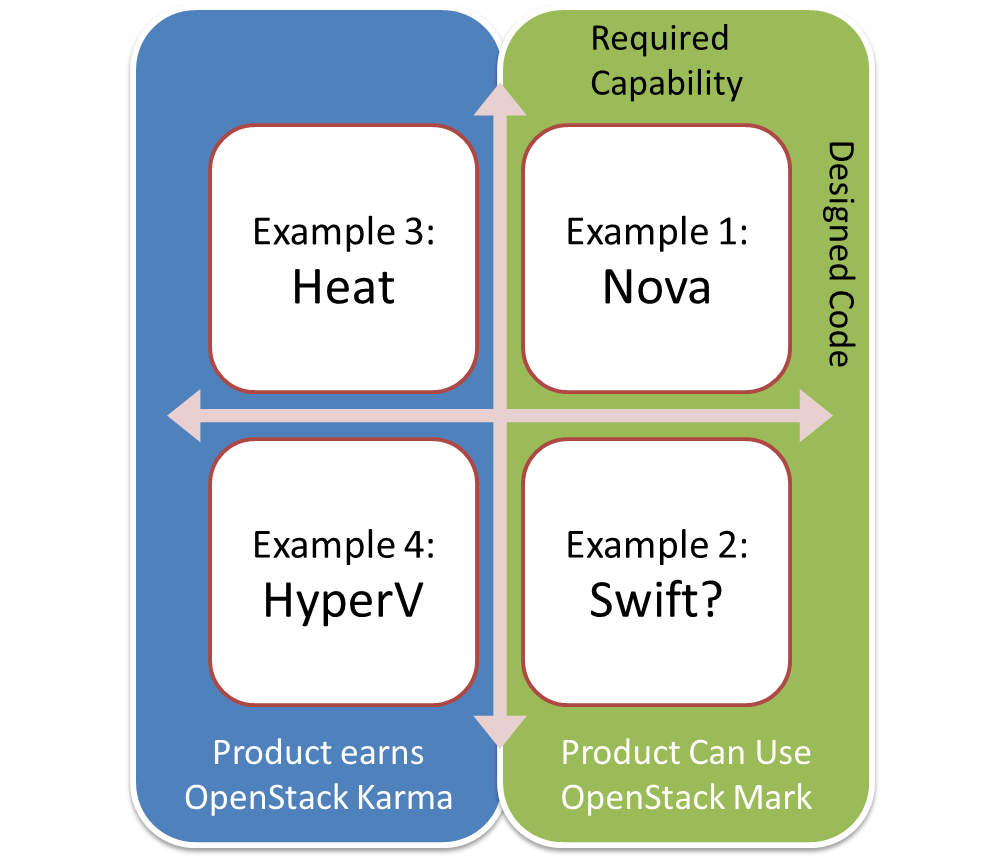
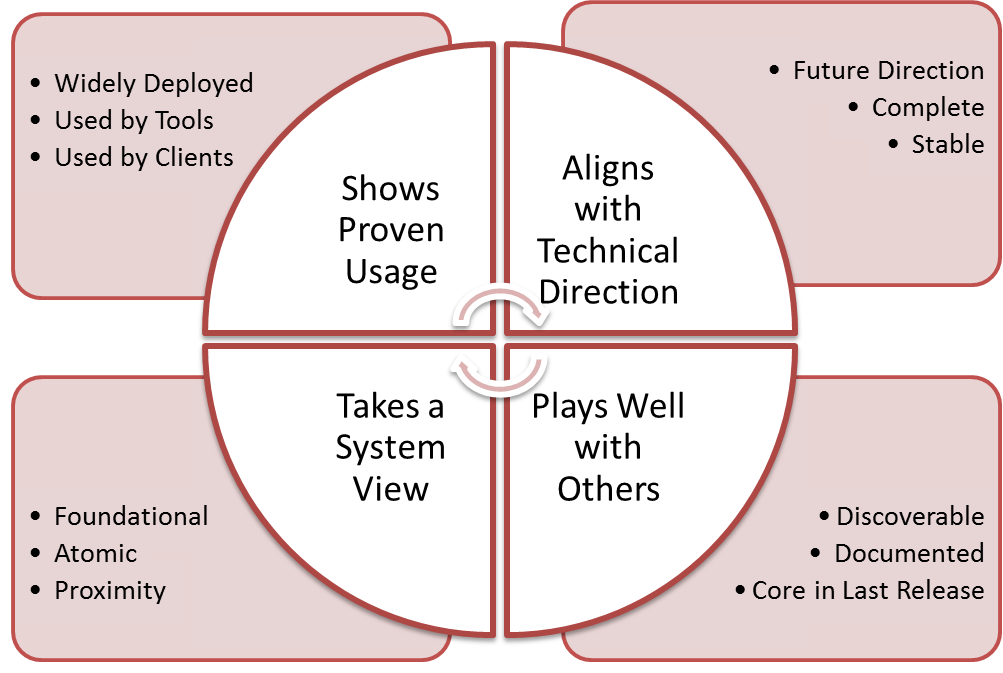
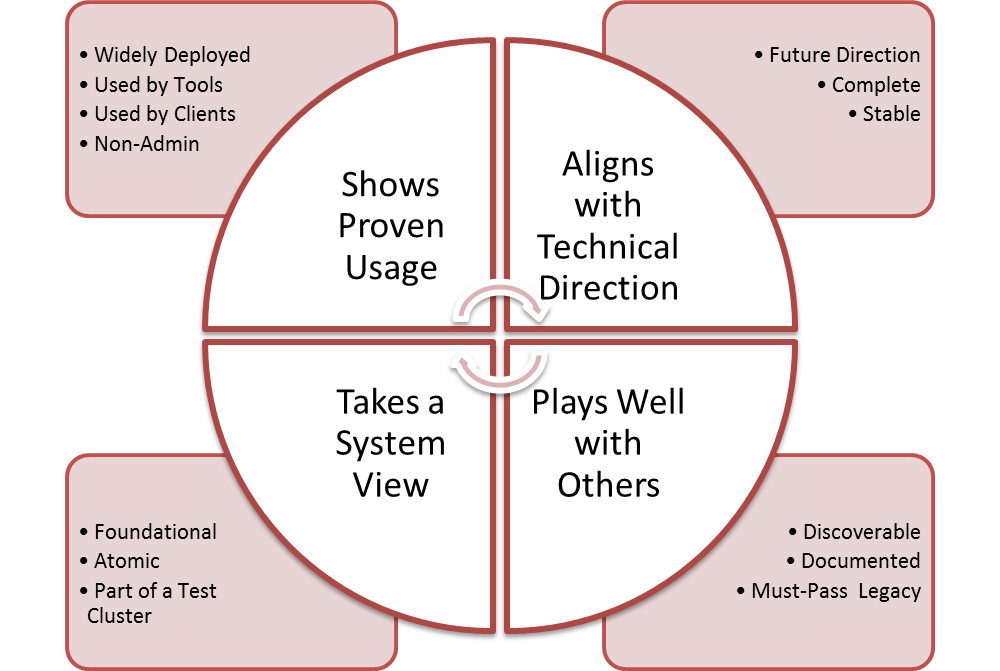
- DefCore criteria were approved by the Board. The overall process and impact was talked about positively at the summit. To accelerate, we need +1s and feedback because “crickets” means we need to go slower. I’ll have to dedicate a future post to next steps and “designated sections.”
- Marketplace! Great turn out by vendors of all types, but I’m not hearing about them making a lot of money from OpenStack (which is needed for them to survive). I like the diversity of the marketplace: consulting, aaServices, installers, networking, more networking, new distros, and ecosystem tools.
- There’s some real growth in aaS services for openstack (database, load balancer, dns, etc). This is the ecosystem that many want OpenStack to drive because it helps displace Amazon cloud. I also heard concerns that to be sure they are pluggable so companies can complete on implementation.
- Lots of process changes to adapt to growing pains. People felt that the community is adapting (yeah!) but were concerned having to re-invent tooling (meh).
There are also challenges that people brought to me:
- Our #1 danger is drama. Users and operators want collaboration and friendly competition. They are turned off by vendor conflict or strong-arming in the community (e.g.: the WSJ Red Hat article and fallout). I’d encourage everyone to breathe more and react less.
- Lack of product management is risking a tragedy of the commons. Helping companies work together and across projects is needed for our collaboration processes to work. I’ll be exploring this with Sean Roberts in future posts.
- Making sure there’s profit being generated from shared code. We need to remember that most of the development is corporate funded so we need to make sure that companies generate revenue. The trend of everyone creating unique distros may indicate a problem.
- We need to be more operator friendly. I know we’re trying but we create distance with operators when we insist on creating new tools instead of using the existing ecosystem. That also slows down dealing with upgrades, resilient architecture and other operational concerns.
- Anointed projects concerns have expanded since Hong Kong. There’s a perception that Heat (orchestration), Triple0 (provisioning), Solum (platform) are considered THE only way OpenStack solves those problems and other approaches are not welcome. While that encourages collaboration, it also chills competition and discussion.
- There’s a lot of whispering about the status of challenged projects: neutron (works with proprietary backends but not open, may not stay integrated) and openstack boot-strap (state of TripleO/Ironic/Heat mix). The issue here is NOT if they are challenged but finding ways to discuss concerns openly (see anointed projects concern).
I’d enjoy hearing more about success and deeper discussion around concerns. I use community feedback to influence my work in the community and on the board. If you think I’ve got it right or wrong then please let me know.