Server management interfaces stink. They are inconsistent both between vendors and within their own product suites. Ideally, Vendors would agree on a single API; however, it’s not clear if the diversity is a product of competition or actual platform variation. Likely, it’s both.
 What is Redfish? It’s a REST API for server configuration that aims to replace both IPMI and vendor specific server interfaces (like WSMAN). Here’s the official text from RedfishSpecification.org.
What is Redfish? It’s a REST API for server configuration that aims to replace both IPMI and vendor specific server interfaces (like WSMAN). Here’s the official text from RedfishSpecification.org.
Redfish is a modern intelligent [server] manageability interface and lightweight data model specification that is scalable, discoverable and extensible. Redfish is suitable for a multitude of end-users, from the datacenter operator to an enterprise management console.
I think that it’s great to see vendors trying to get on the same page and I’m optimistic that we could get something better than IPMI (that’s a very low bar). However, I don’t expect that vendors can converge to a single API; it’s just not practical due to release times and pressures to expose special features. I think the divergence in APIs is due both to competitive pressures and to real variance between platforms.
Even if we manage to a grand server management unification; the problem of interface heterogeneity has a long legacy tail.
In the best case reality, we’re going from N versions to N+1 (and likely N*2) versions because the legacy gear is still around for a long time. Adding Redfish means API sprawl is going to get worse until it gets back to being about the same as it is now.
Putting pessimism aside, the sprawl problem is severe enough that it’s worth supporting Redfish on the hope that it makes things better.
That’s easy to say, but expensive to do. If I was making hardware (I left Dell in Oct 2014), I’d consider it an expensive investment for an uncertain return. Even so, several major hardware players are stepping forward to help standardize. I think Redfish would have good ROI for smaller vendors looking to displace a major player can ride on the standard.
Redfish is GREAT NEWS for me since RackN/Crowbar provides hardware abstraction and heterogeneous interface support. More API variation makes my work more valuable.
One final note: if Redfish improves hardware security in a real way then it could be a game changer; however, embedded firmware web servers can be tricky to secure and patch compared to larger application focused software stacks. This is one area what I’m hoping to see a lot of vendor collaboration! [note: this should be it’s own subject – the security issue is more than API, it’s about system wide configuration. stay tuned!]
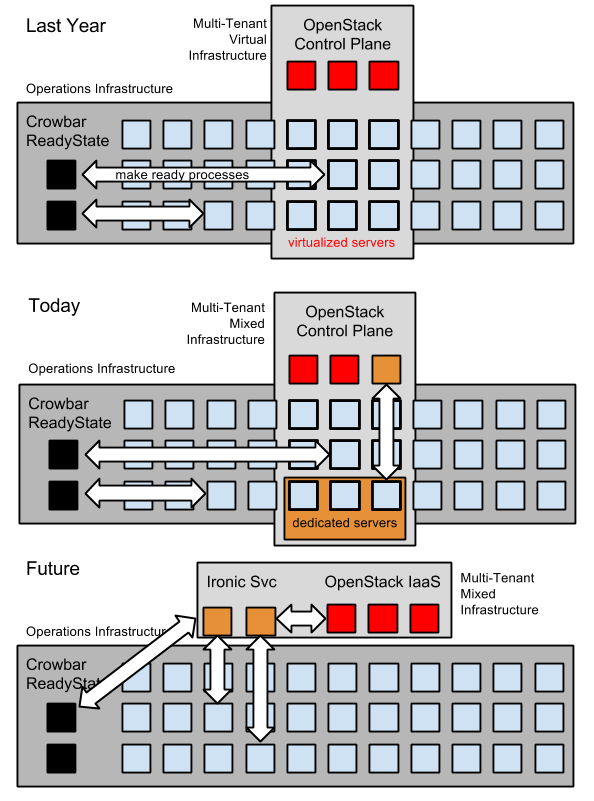





 Today, we’re ready to help people run and expand OpenCrowbar (days away from v2.1!). We’re also seeking investment to make the project more “enterprise-ready” and build integrations that extend ready state.
Today, we’re ready to help people run and expand OpenCrowbar (days away from v2.1!). We’re also seeking investment to make the project more “enterprise-ready” and build integrations that extend ready state. Author’s 2/26/2015 Note: This proposal was approved by the Board in October 2014.
Author’s 2/26/2015 Note: This proposal was approved by the Board in October 2014.