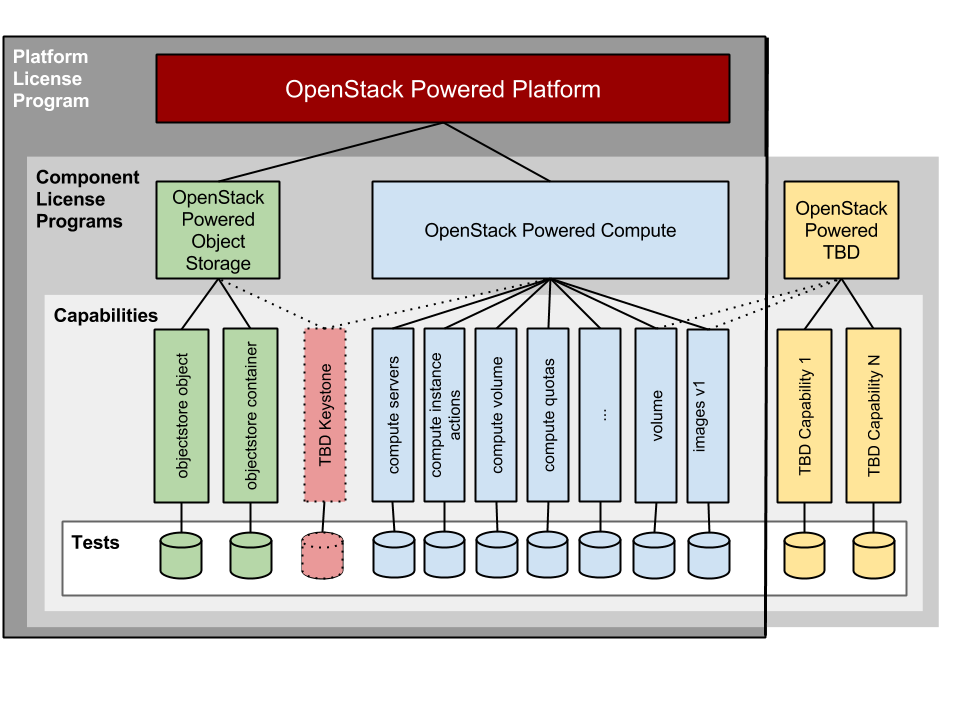
OpenStack DefCore Committee has established the principles and first artifacts required for vendors using the OpenStack trademark. Over the next release cycle, we will be applying these to the Ice House and Juno releases.
 Learn more? Hear about it LIVE! Rob will be doing two sessions about DefCore next week (will be recorded):
Learn more? Hear about it LIVE! Rob will be doing two sessions about DefCore next week (will be recorded):
- Tues Dec 16 at 9:45 am PST- OpenStack Podcast #14 with Jeff Dickey
- Thurs Dec 18 at 9:00 am PST – Online Meetup about DefCore with Rafael Knuth (optional RSVP)
At the December 2014 OpenStack Board meeting, we completed laying the foundations for the DefCore process that we started April 2013 in Portland. These are a set of principles explaining how OpenStack will select capabilities and code required for vendors using the name OpenStack. We also published the application of these governance principles for the Havana release.
- The OpenStack Board approved DefCore principles to explain
the landscape of core including test driven capabilities and designated code (approved Nov 2013) - the twelve criteria used to select capabilities (approved April 2014)
- the creation of component and framework layers for core (approved Oct 2014)
- the ten principles used to select designated sections (approved Dec 2014)
To test these principles, we’ve applied them to Havana and expressed the results in JSON format: Havana Capabilities and Havana Designated Sections. We’ve attempted to keep the process transparent and community focused by keeping these files as text and using the standard OpenStack review process.
DefCore’s work is not done and we need your help! What’s next?
- Vote about bylaws changes to fully enable DefCore (change from projects defining core to capabilities)
- Work out going forward process for updating capabilities and sections for each release (once authorized by the bylaws, must be approved by Board and TC)
- Bring Havana work forward to Ice House and Juno.
- Help drive Refstack process to collect data from the field
 What is Redfish? It’s a REST API for server configuration that aims to replace both IPMI and vendor specific server interfaces (like WSMAN). Here’s the official text from
What is Redfish? It’s a REST API for server configuration that aims to replace both IPMI and vendor specific server interfaces (like WSMAN). Here’s the official text from 





 Author’s 2/26/2015 Note: This proposal was approved by the Board in October 2014.
Author’s 2/26/2015 Note: This proposal was approved by the Board in October 2014.