A collaboration with Michael Still (TC Member from Rackspace) & Joshua McKenty and Cross posted by Rackspace.
After nearly a year of discussion, the OpenStack board launched the DefCore process with 10 principles that set us on path towards a validated interoperability standard. We created the concept of “designated sections” to address concerns that using API tests to determine core would undermine commercial and community investment in a working, shared upstream implementation.
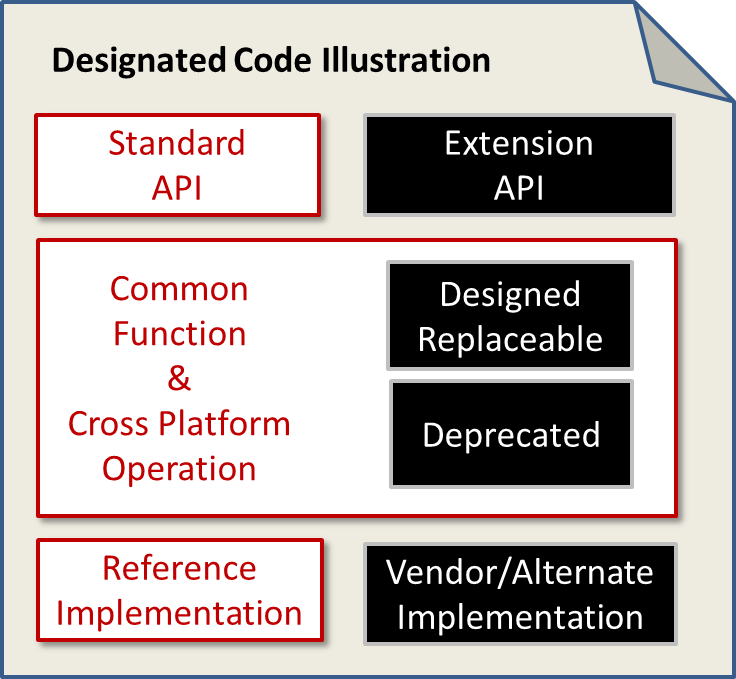 Designated sections provides the “you must include this” part of the core definition. Having common code as part of core is a central part of how DefCore is driving OpenStack operability.
Designated sections provides the “you must include this” part of the core definition. Having common code as part of core is a central part of how DefCore is driving OpenStack operability.
So, why do we need this?
From our very formation, OpenStack has valued implementation over specification; consequently, there is a fairly strong community bias to ensure contributions are upstreamed. This bias is codified into the very structure of the GNU General Public License (GPL) but intentionally missing in the Apache Public License (APL v2) that OpenStack follows. The choice of Apache2 was important for OpenStack to attract commercial interests, who often consider GPL a “poison pill” because of the upstream requirements.
Nothing in the Apache license requires consumers of the code to share their changes; however, the OpenStack foundation does have control of how the OpenStack™ brand is used. Thus it’s possible for someone to fork and reuse OpenStack code without permission, but they cannot called it “OpenStack” code. This restriction only has strength if the OpenStack brand has value (protecting that value is the primary duty of the Foundation).
This intersection between License and Brand is the essence of why the Board has created the DefCore process.
Ok, how are we going to pick the designated code?
Figuring out which code should be designated is highly project specific and ultimately subjective; however, it’s also important to the community that we have a consistent and predictable strategy. While the work falls to the project technical leads (with ratification by the Technical Committee), the DefCore and Technical committees worked together to define a set of principles to guide the selection.
This Technical Committee resolution formally approves the general selection principles for “designated sections” of code, as part of the DefCore effort. We’ve taken the liberty to create a graphical representation (above) that visualizes this table using white for designated and black for non-designated sections. We’ve also included the DefCore principle of having an official “reference implementation.”
Here is the text from the resolution presented as a table:
| Should be DESIGNATED: | Should NOT be DESIGNATED: |
|
|
The resolution includes the expectation that “code that is not clearly designated is assumed to be designated unless determined otherwise. The default assumption will be to consider code designated.”
This definition is a starting point. Our next step is to apply these rules to projects and make sure that they provide meaningful results.
Wow, isn’t that a lot of code?
Not really. Its important to remember that designated sections alone do not define core: the must-pass tests are also a critical component. Consequently, designated code in projects that do not have must-pass tests is not actually required for OpenStack licensed implementation.
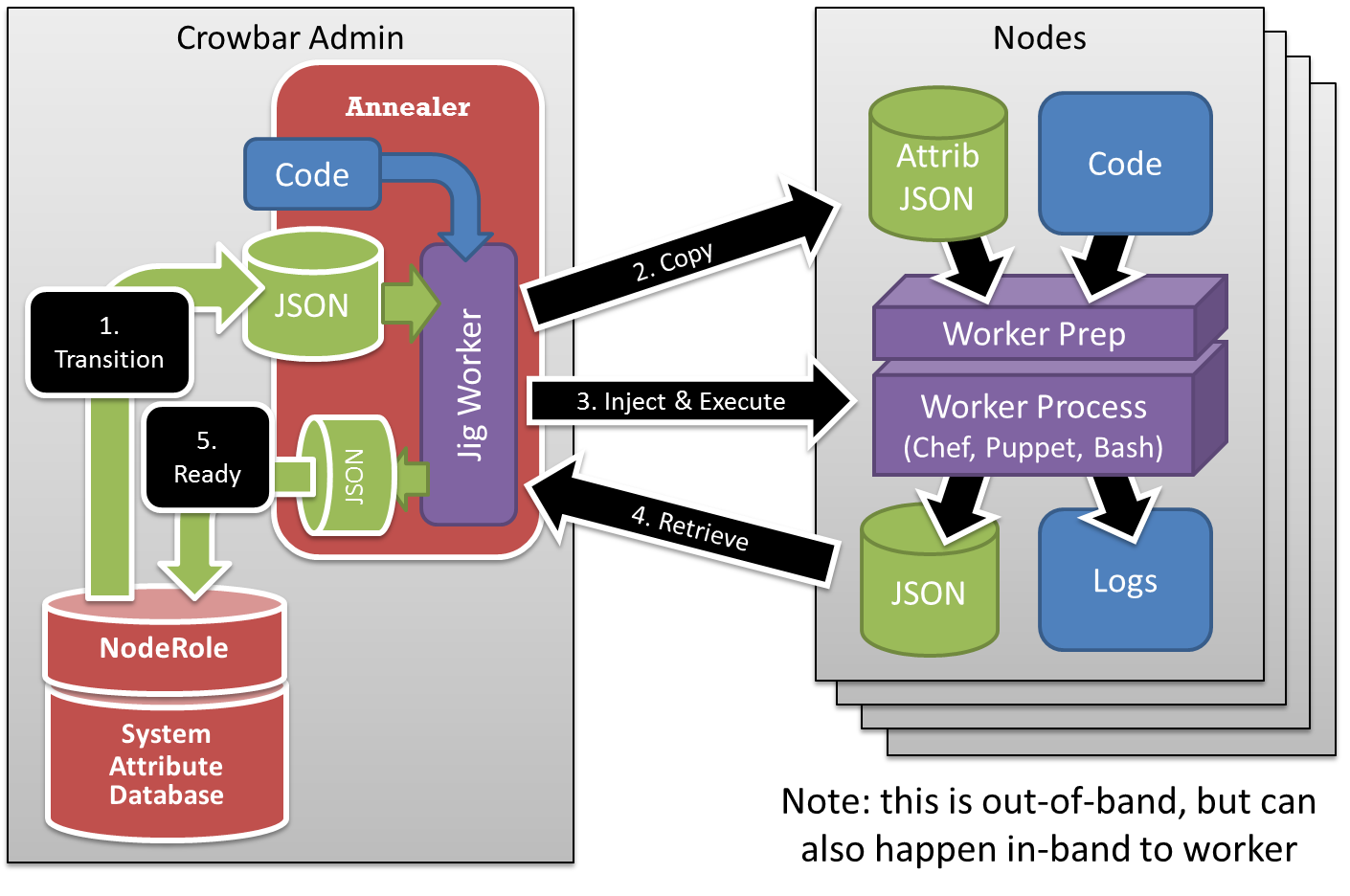
 Emergent services
Emergent services