This posted started from a discussion with Judd Maltin that he documented in a post about “wanting a composable run deck.”
 I’ve had several conversations comparing OpenCrowbar with other “bare metal provisioning” tools that do thing like serve golden images to PXE or IPXE server to help bootstrap deployments. It’s those are handy tools, they do nothing to really help operators drive system-wide operations; consequently, they have a limited system impact/utility.
I’ve had several conversations comparing OpenCrowbar with other “bare metal provisioning” tools that do thing like serve golden images to PXE or IPXE server to help bootstrap deployments. It’s those are handy tools, they do nothing to really help operators drive system-wide operations; consequently, they have a limited system impact/utility.
In building the new architecture of OpenCrowbar (aka Crowbar v2), we heard very clearly to have “less magic” in the system. We took that advice very seriously to make sure that Crowbar was a system layer with, not a replacement to, standard operations tools.
Specifically, node boot & kickstart alone is just not that exciting. It’s a combination of DHCP, PXE, HTTP and TFTP or DHCP and an IPXE HTTP Server. It’s a pain to set this up, but I don’t really get excited about it anymore. In fact, you can pretty much use open ops scripts (Chef) to setup these services because it’s cut and dry operational work.
Note: Setting up the networking to make it all work is perhaps a different question and one that few platforms bother talking about.
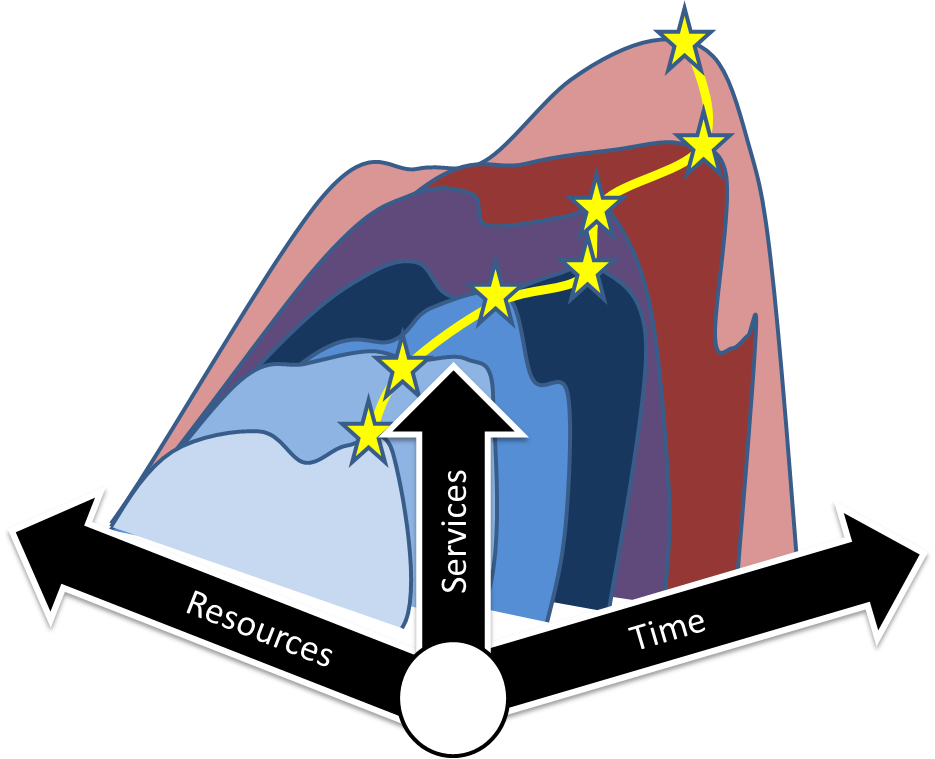
So, if doing node provisioning is not a big deal then why is OpenCrowbar important? Because sustaining operations is about ongoing system orchestration (we’d say an “operations model“) that starts with provisioning.
It’s not the individual services that’s critical; it’s doing them in a system wide sequence that’s vital.
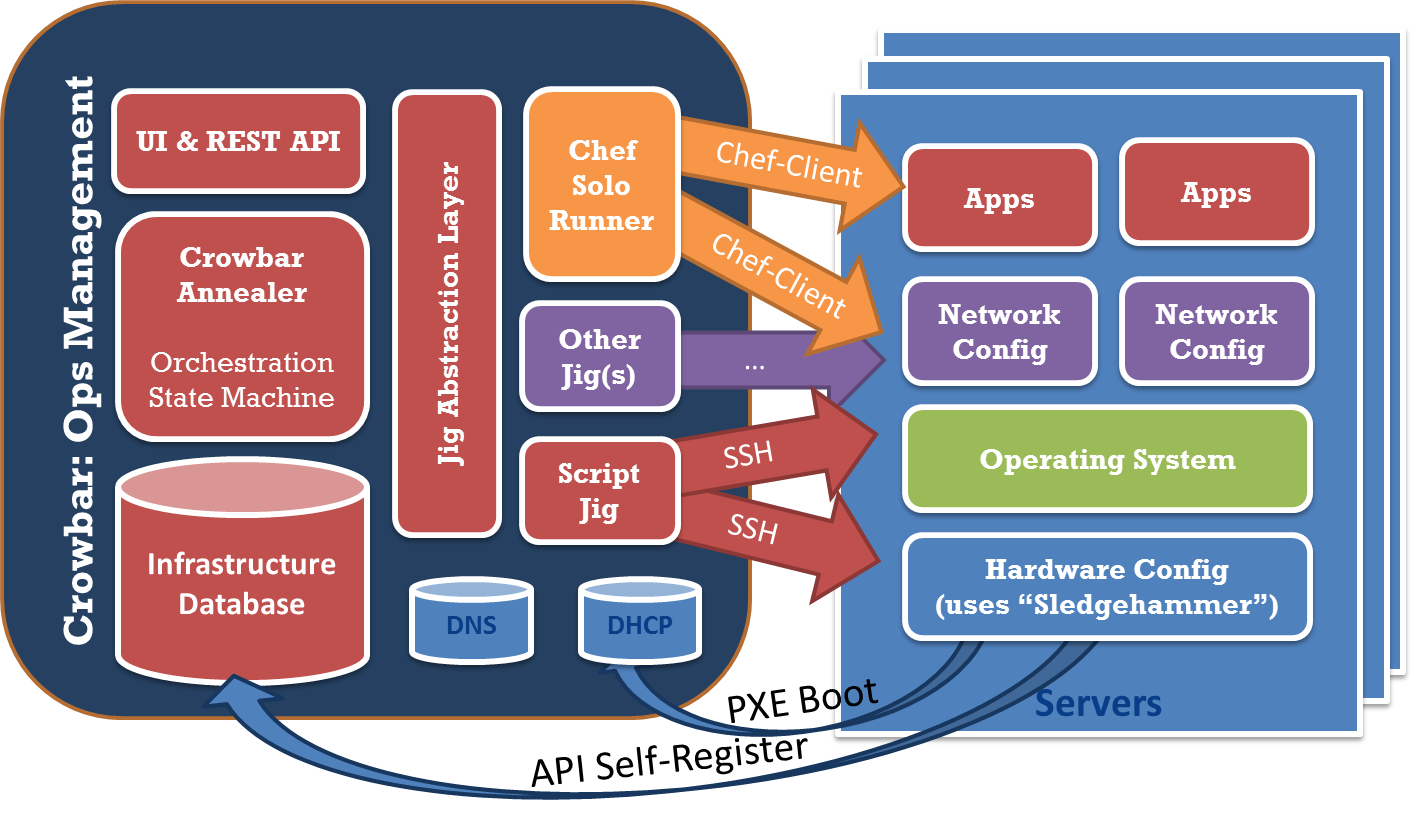
Crowbar does NOT REPLACE the services. In fact, we go out of our way to keep your proven operations tool chain. We don’t want operators to troubleshoot our IPXE code! We’d much rather use the standard stuff and orchestrate the configuration in a predicable way.
In that way, OpenCrowbar embraces and composes the existing operations tool chain into an integrated system of tools. We always avoid replacing tools. That’s why we use Chef for our DSL instead of adding something new.
What does that leave for Crowbar? Crowbar is providing a physical infratsucture targeted orchestration (we call it “the Annealer”) that coordinates this tool chain to work as a system. It’s the system perspective that’s critical because it allows all of the operational services to work together.
For example, when a node is added then we have to create v4 and v6 IP address entries for it. This is required because secure infrastructure requires reverse DNS. If you change the name of that node or add an alias, Crowbar again needs to update the DNS. This had to happen in the right sequence. If you create a new virtual interface for that node then, again, you need to update DNS. This type of operational housekeeping is essential and must be performed in the correct sequence at the right time.
The critical insight is that Crowbar works transparently alongside your existing operational services with proven configuration management tools. Crowbar connects links in your tool chain but keeps you in the driver’s seat.


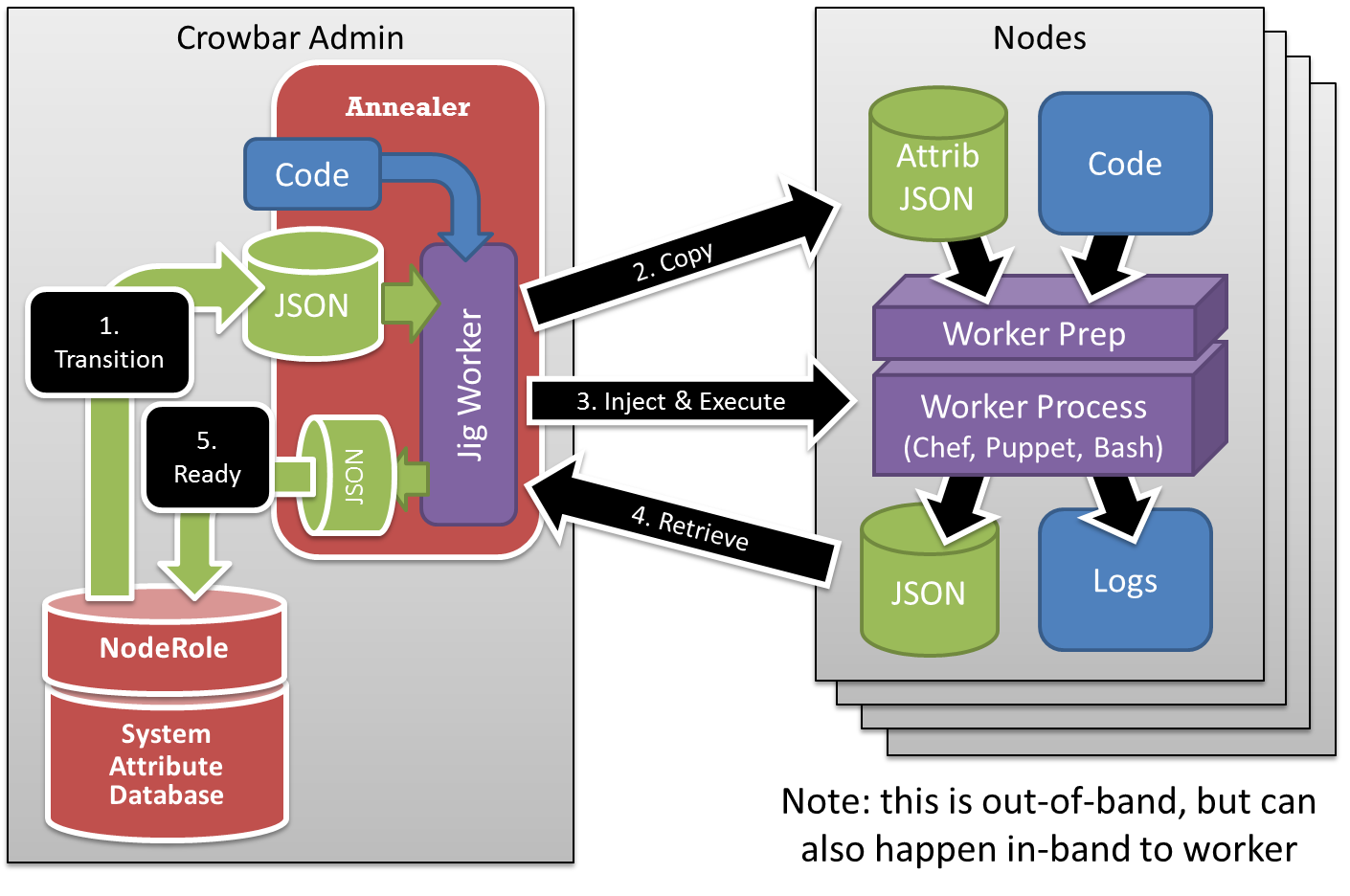
 Emergent services
Emergent services