This post is the second in a 4 part series about Success factors for Operating Open Source Infrastructure.
 When we look at reference deployments, there are several things that make a good referenced deployment; and ones that are useful by the community.
When we look at reference deployments, there are several things that make a good referenced deployment; and ones that are useful by the community.
First, a referenced deployment needs to be specific and useful. They have to be identified as solving a specific problem using the software. And they have to have a specific configuration that can be described in a way that creates a workable scenario for that. There may be multiple useful reference implementations. And in that case, each one needs to be identified as the – by the expected behavior. For example, our deployments include a compute centric configuration that has hardware configurations and network configurations adapted to compute focused applications.
They also have storage focused applications that are specifically targeted at enabling cheap and deep storage nodes for that type of situation. Both configurations are important and valid but they require different implementations, different details and different reference architectures. As long as it is clear that there are multiple patterns, the community is perfectly able to absorb and use these patterns.
Establishment of a widely adopted best practice is a central success criteria for any project.
Best practices ensure that deployers of the technology cannot only purchase implementations that will be successful, but they can also compare notes to work with their community. A significant adoption curve happens after the establishment of these best practices because at that point, the risk of purchase dramatically drops, and the ability to support radically increases. The next thing that’s important in the establishment of these technologies is that that reference implementation or the reference architecture has a way to be configured in a repeatable way.
Very often, this takes the form of deployment books from manuals. While useful in small deployments, in a hyperscale deployment the books really have diminishing value. This is because the level of human error – the chance of making a fundamental mistake during configuration – increases exponentially with the number of nodes, because each node is tightly interconnected with other nodes within the system.
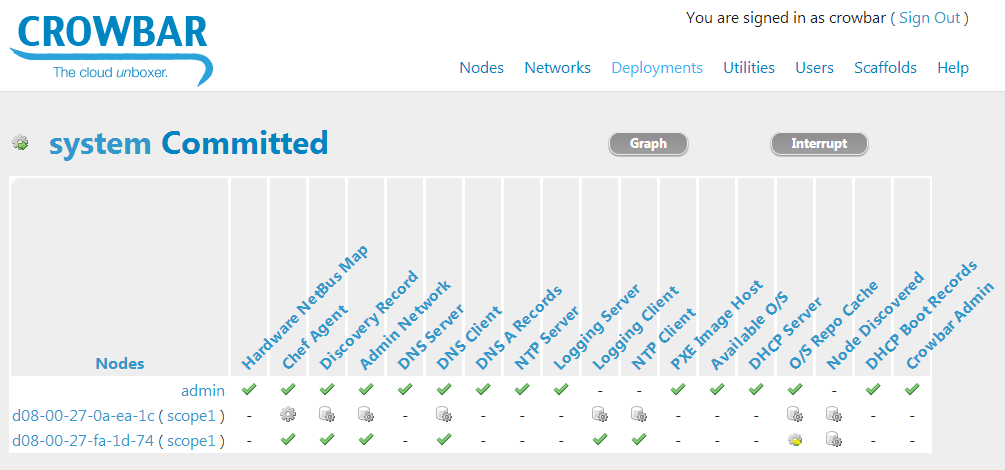
My team at Dell launched the Crowbar project as a way to reduce or mitigate this effort substantially. We recognized that the number one cause of delays and impacts in time to value in a hyperscale deployment is configuration and set-up. Any simple mistake made during configuration, even down to ordering of the gear, or physical defects within the infrastructure, will create dramatic delays in troubleshooting and diagnosing those issues. By automating the process, we have ensured that we can bootstrap the system quickly.
The goal of automated best practice is to bootstrap in a conforming and repeatable way. This enables the community to work together immediately towards return on investment, and greatly reduces the risk of problems caused by human error. For example, it’s typical within a site for us to find that network configurations do not match the specifications. In many cases, we find issues with the core networking infrastructure not matching the way it was originally designed. We also find failures on physical infrastructure, disk failures, system mismatches,and unanticipated configuration. Any one of these problems with a human setup might be missed or overlooked.
Validated reference architectures, while valuable, are no longer sufficient. Automated reference configurations have become the key to successfully delivered solutions.
Interested in more? Read part 3