In part pt 1, we reviewed the RackN team’s hard won insights from previous deployment automation. We feel strongly that prioritizing portability in provisioning automation is important. Individual sites may initially succeed building just for their own needs; however, these divergences limit future collaboration and ultimately make it more expensive to maintain operations.
 If it’s more expensive isolate then why have we failed to create shared underlay? Very simply, it’s hard to encapsulate differences between sites in a consistent way.
If it’s more expensive isolate then why have we failed to create shared underlay? Very simply, it’s hard to encapsulate differences between sites in a consistent way.
What makes cluster construction so hard?
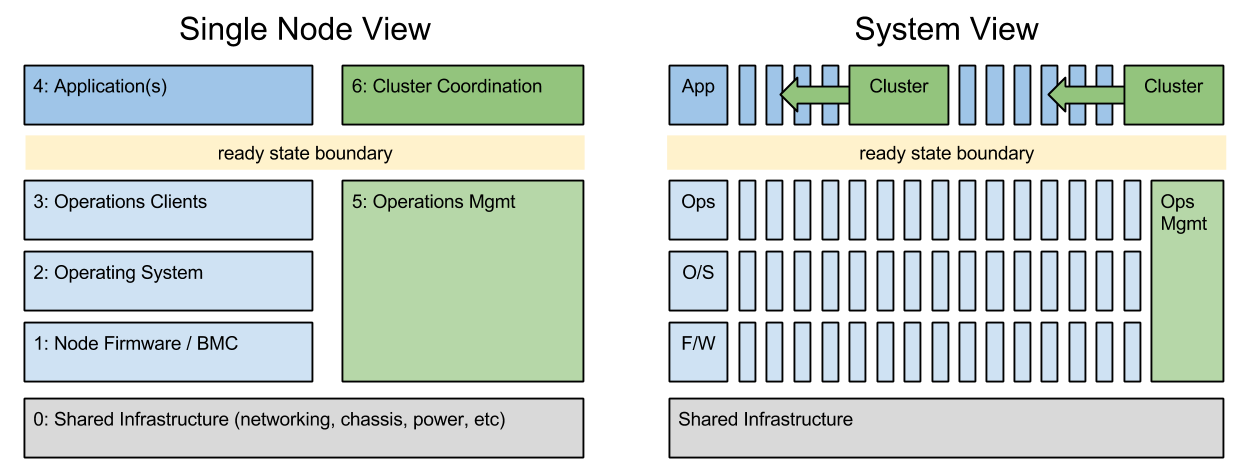
There are a three key things we have to solve together: cross-node dependencies (linking), a lack of service configuration (services) and isolating attribute chains (configuration). While they all come back to thinking of the whole system as a cluster instead of individual nodes. let’s break them down:
Cross Dependencies (Cluster Linking) – The reason for building a multi-node system, is to create an interconnected system. For example, we want a database cluster with automated fail-over or we want a storage system that predictably distributes redundant copies of our data. Most critically and most overlooked, we also want to make sure that we can trust cluster members before we share secrets with them.
These cluster building actions require that we synchronize configuration so that each step has the information it requires. While it’s possible to repeatedly bang on the configure until it converges, that approach is frustrating to watch, hard to troubleshoot and fraught with timing issues. Taking this to the next logical steps, doing upgrades, require sequence control with circuit breakers – that’s exactly what Digital Rebar was built to provide.
Service Configuration (Cluster Services) – We’ve been so captivated with node configuration tools (like Ansible) that we overlook the reality that real deployments are intertwined mix of service, node and cross-node configuration. Even after interacting with a cloud service to get nodes, we still need to configure services for network access, load balancers and certificates. Once the platform is installed, then we use the platform as a services. On physical, there are even more including DNS, IPAM and Provisioning.
The challenge with service configurations is that they are not static and generally impossible to predict in advance. Using a load balancer? You can’t configure it until you’ve got the node addresses allocated. And then it needs to be updated as you manage your cluster. This is what makes platforms awesome – they handle the housekeeping for the apps once they are installed.
Digital Rebar decomposition solves this problem because it is able to mix service and node configuration. The orchestration engine can use node specific information to update services in the middle of a node configuration workflow sequence. For example, bringing a NIC online with a new IP address requires multiple trusted DNS entries. The same applies for PKI, Load Balancer and Networking.
Isolating Attribute Chains (Cluster Configuration) – Clusters have a difficult duality: they are managed as both a single entity and a collection of parts. That means that our configuration attributes are coupled together and often iterative. Typically, we solve this problem by front loading all the configuration. This leads to several problems: first, clusters must be configured in stages and, second, configuration attributes are predetermined and then statically passed into each component making variation and substitution difficult.
Our solution to this problem is to treat configuration more like functional programming where configuration steps are treated as isolated units with fully contained inputs and outputs. This approach allows us to accommodate variation between sites or cluster needs without tightly coupling steps. If we need to change container engines or networking layers then we can insert or remove modules without rewriting or complicating the majority of the chain.
This approach is a critical consideration because it allows us to accommodate both site and time changes. Even if a single site remains consistent, the software being installed will not. We must be resilient both site to site and version to version on a component basis. Any other pattern forces us to into an unmaintainable lock step provisioning model.
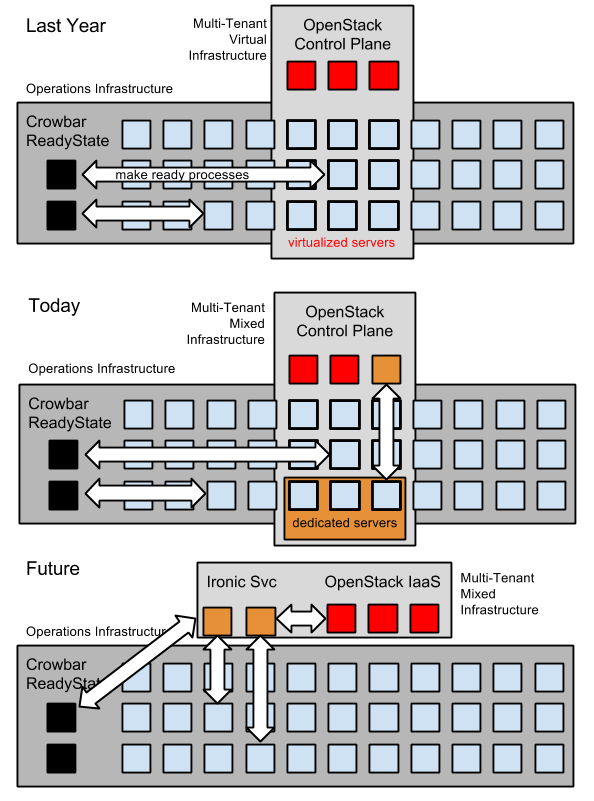
To avoid solving these three hard issues in the past, we’ve built provisioning monoliths. Even worse, we’ve seen projects try to solve these cluster building problems within their own context. That leads to confusing boot-strap architectures that distract from making the platforms easy for their intended audiences. It is OK for running a platform to be a different problem than using the platform.
In summary, we want composition because we are totally against ops magic. No unicorns, no rainbows, no hidden anything.
Basically, we want to avoid all magic in a deployment. For scale operations, there should never be a “push and prey” step where we are counting on timing or unknown configuration for it to succeed. Those systems are impossible to maintain, share and scale.
I hope that this helps you look at the Digital Rebar underlay approach in a holistic why and see how it can help create a more portable and sustainable IT foundation.
 Overall, Dockercon did a good job connecting Docker users with information. In some ways, it was a very “let’s get down to business” conference without the open source collaboration feel of previous events. For enterprise customers and partners, that may be a welcome change.
Overall, Dockercon did a good job connecting Docker users with information. In some ways, it was a very “let’s get down to business” conference without the open source collaboration feel of previous events. For enterprise customers and partners, that may be a welcome change. Last week,
Last week,  This week, we added Install Wizard templates to the
This week, we added Install Wizard templates to the